
























































.svg)




































It’s one of the most-famous business expressions: “If you can’t measure it, you can’t manage it.”
The idea – that good management requires good data – is even more powerful and relevant in the 21st century, thanks to two sweeping trends. First, we are entering the era of data-driven business. Pioneered by Uber, Airbnb, Facebook and others, companies are leveraging operational data in mission-critical ways that transform their business and disrupt markets.
Second, the speed of business and the rate at which data is created are both accelerating. As a result of all this change is that business decisions are now, more than ever, being made in real- or near-real time. To maintain that pace of business operations, enterprises need continuous access to real-time data that is valid and accurate, and is orchestrated with other meaningful data to make it usable for business decision-making.
Within data teams, this has two huge implications. First, when your company becomes data driven, data becomes your lifeblood. It flows through all your mission-critical business processes. Viewed through that lens, how you engineer maximum value from your data investments as well as optimize all of your data-related costs – including storage, transport, management, analytics, security, data quality and reliability, and more – has a huge direct impact on your company’s bottom line.
Second, your business cannot rely on IT and data monitoring technology from the 20th century to manage and optimize data usage and costs in the 21st century. Nor can it rely on an application-centric observability solution such as application performance monitoring (APM) that treats data as an afterthought.
Businesses need a holistic, AI-infused platform that can track, manage, and optimize your data wherever it operates and travels, and they need it done in real time. The platform that provides this, and ensures the health of the all-important data pipelines, is data observability.
In this blog, I’ll define what value engineering and data cost optimization mean for modern data operations today, explain what’s changed in the last decade that makes these practices so essential today, and finally discuss how a data observability platform is the key enabler for businesses to deploy value engineering best practices, while also achieving data cost optimization.
Value Engineering, FinOps, and Cost Optimization for Modern Data Environments
Broadly speaking, value engineering is about building a product or service for maximum “value," defined as function (or performance, or output) relative to cost (in dollars, man-hours, or some other metric). Within software and IT, value engineering has evolved into a whole approach akin to lean and agile development in which costs and benefits are constantly measured in order to enable continuous improvement.
The data-driven rigor of value engineering accelerates project development times, enables quick pivots as conditions change, and prevents scope creep or worse, boiling the ocean behavior. This ensures innovation delivers value to both internal stakeholders and external clients.
The data-driven approach to value engineering is in harmony with today’s data-driven, business systems. Data-driven companies by definition cannot afford any data downtime. By gathering constant data on performance, downtime, and costs, value engineering seeks to minimize downtime or, through the use of machine learning and predictive analytics, prevent it from happening.
Data cost optimization is similar to value engineering, though more narrow in focus. Whereas practitioners of value engineering sometimes define the variables of performance, cost and value in fuzzier, abstract terms, data cost optimization gets down to dollars and cents: dollars spent, revenue and sales gained, and actual ROI.
Therefore, data cost optimization should not be just about efficiency and cost cutting. Practiced properly, data cost optimization is about playing both offense and defense. In other words, maximizing the performance of your data, minimizing data downtime from bottlenecks or quality issues, and streamlining your data infrastructure.
Closely related to data cost optimization is the modern discipline of FinOps. FinOps arose to meet the difficult challenge of controlling costs and maximizing ROI of your cloud data. Cloud data costs are operational expenditures such as storage and processing fees. They can vary wildly by volume, time of day, and other factors within and outside of an organization’s control. That makes them much harder to manage and forecast than traditional data investments, such as purchases of server hardware, software licenses, storage disks, etc. that can be simply amortized over a predictable lifespan.
Whereas data cost optimization practitioners have a holistic 360-degree view of a company’s data costs, FinOps experts want to zero in on the specifics of enabling accurate chargebacks of data pipeline and storage costs by department. This granular point–of-view is important because it helps create a culture of accountability and data reuse that directly supports the macro goal of data cost optimization.
The Relationship Between FinOps and Data Pipelines
Here’s an example of data cost optimization and FinOps approaches at work:
Imagine a product team wants to create a real-time recommendation engine for the company’s shopping web site. To be effective, the recommendations must be delivered instantly and, for highest relevance, based on the most recent things that the customer has viewed. Working with the data engineers, they have priced out the ongoing costs of a data application querying a real-time analytics database in the cloud that continuously ingests data from multiple sources, from the site’s product inventory to customer clickstreams. That data application must then deliver recommendations to customers in milliseconds.
This is a complicated data pipeline that will not only take plenty of effort and money to build, but will have dynamic ongoing costs and revenue due to sales, holidays, and more. The product team and data engineers would track sales generated by the recommendation engine and the ongoing costs of the underlying data pipeline to determine their ROI. They might also perform A/B tests to see if accelerating the engine’s results by spending more on the data pipeline delivers more ROI. In other words, using FinOps and data cost optimization, they can determine whether the project is delivering maximum revenue and value, or whether investing more could deliver even more.
However, to have the visibility into your data infrastructure to make these calculations, as well as the ability to make changes if desired, requires your DataOps team to be empowered with the right platform.
The Problem with Random Acts of Agile
Besides the complications of calculating operating expenses and value, there’s another side effect of the rise of the cloud in the last decade. Business units frustrated by command-and-control-focused IT departments have, on their own, rushed to deploy cloud services that are easier to use and scale. Sales and marketing teams became hooked on Salesforce, developers moved apps and storage to AWS, and data engineers embraced cloud data warehouses.
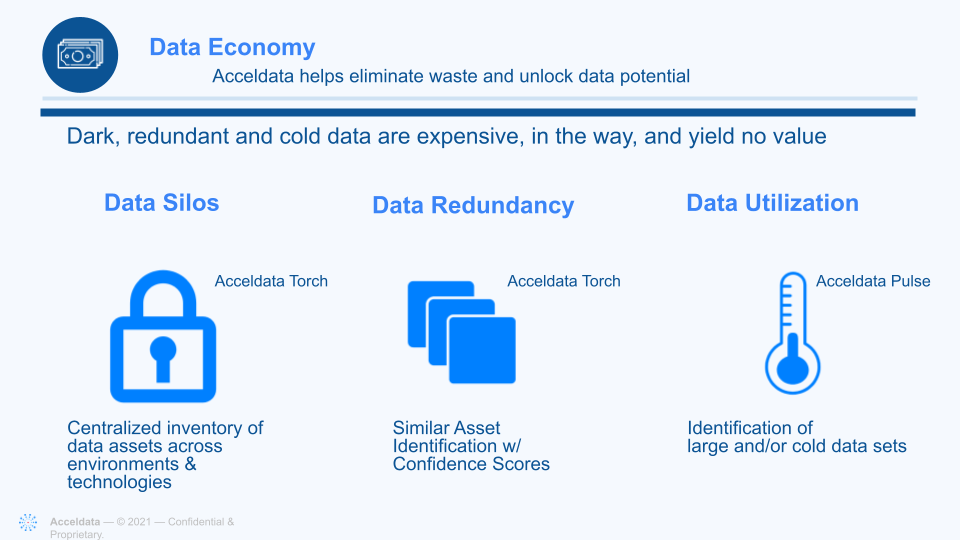
Over time, the costs of such random acts of agile added up. There was rampant and expensive duplication of data in hard-to-find cloud repositories. Sometimes these were data silos owned by a particular team that were inaccessible to others. Other times, they were forgotten pools of “dark data” that sat unused but still cost organizations every month. Either way, it’s an epidemic, with an estimated 60-73% of data stored by companies going unused.
The unmanaged growth of data pipelines exacerbated data duplication issues, while also increasing the number of data errors, outdated datasets, and issues with data reliability. The more that data travels through a data pipeline, the more times it can be transformed, aggregated, mislabeled, corrupted, etc. This reduces the trust and usefulness of data, and creates expensive cleanup work for data engineers.
Here’s an example. Imagine a company has built an ML model using a well-engineered data pipeline that took its data engineers many work hours. A second team wants to build an application using almost the same data. With a bit of incremental work, data engineers could enable the original pipeline to serve both two applications.
What if a lack of data discovery tools meant that no one was aware of the similarities of the original and proposed pipelines? Or maybe the second team is leery because of prior experiences with reusing data sets that turned out to be of poor quality. Or perhaps the company lacks the tools to track and divide data pipeline costs accurately between the two business teams. The net result is that the second team insists on building a whole new pipeline from scratch.
The Solution: Data Observability
A neutral multidimensional data observability platform provides all of the missing features above. This empowers data engineers with the real-time visibility, intelligence and control to build a culture of value engineering and data reuse that optimizes not just ongoing costs, but also ROI.
The Acceldata Data Observability platform provides automated ongoing data discovery and cataloging. This ensures that all datasets wherever they are stored are visible to all users in the system through a centralized inventory. This prevents the growth of data silos that are expensive to store, create trust and data quality issues, as well as security risks.
The Acceldata platform goes one step further to proactively eliminate duplicate and redundant data. It uses machine learning to automatically identify datasets and tag data. These metadata tags help describe the data’s freshness, its lineage and dependencies to other datasets, where it is used, and more. This enables data engineers to find datasets that are old, unused, drifted, and eliminate them or move them to cheaper cold storage, and improve the data quality of the remaining datasets.
Acceldata also enables potential users to easily sift through and find the best datasets for their application, and give them the context to trust that their choice won’t result in unexpected results or errors that raise hackles in the executive suites. This creates a culture of efficiency and reuse that reduces the demand for new datasets and data pipelines, slashing the work of your data engineers.
With Acceldata's data profiling capabilities also help companies ensure error-free data migrations to the cloud.
provides real-time performance tracking of your data sets and data pipelines, as well as analytics to detect anomalies that could be problems now, or patterns that predict future problems. This helps companies fix and prevent unplanned outages or slowdowns that can cost data-driven companies millions of dollars in lost sales. It also helps companies rightsize their infrastructure and cloud costs to save millions, even while meeting their customer SLAs.
Additionally, the Acceldata platform also lets companies track and predict their data operation costs, not just to the individual pipeline, but to the individual application or user. This enables accurate chargebacks to different departments and users, and allows companies to calculate the value or ROI generated by a particular data-driven application or business process. It further reduces data costs by enabling you to automate operations and manage thousands of data pipelines with fewer data engineers, while abiding by your key SLAs.
Managing data, its costs and its benefits are mission-critical for data-driven organizations. To do so, you need to measure what is happening. The best solution for providing that real-time data, visibility and control is a multidimensional data observability platform like Acceldata.
Photo by Pawel Czerwinski on Unsplash









