What is Data Observability? The 6-Pillar Framework for Zero-Downtime Data (2025)
Data observability is the key to data optimization for managing modern data operations and building data products.
Data observability gives data teams a deep, clear, and actionable understanding of the internal state of their data environment based on its external outputs. In the context of data management, observability refers to the ability to understand the health and state of data in a system. This includes things like data cleanliness, schema consistency, and data lineage.
Continue reading to explore all about data observability, the best approaches to managing data, and the benefits of data observability.
What is Data Observability? (And Why It’s Not Just Monitoring)
Data observability is the process by which enterprise data is monitored for health, accuracy, and usefulness. The primary purpose of a data observability platform is to enable data engineers with the ability to deliver reliable, accurate data which is used to develop data products and apply that data across all areas of an organization for optimal business decision-making.
Data Observability According to Gartner
A recent Gartner Research report presents a comprehensive overview of the concept of "Data Observability" and highlights its increasing importance in today's data management landscape. According to the report, Data Observability is now considered a critical requirement to both support and enhance existing and modern data management architectures.
Specifically, Gartner stated:
“Data observability is the ability of an organization to have a broad visibility of its data landscape and multilayer data dependencies (like data pipelines, data infrastructure, data applications) at all times with an objective to identify, control, prevent, escalate and remediate data outages rapidly within expectable SLAs. Data observability uses continuous multilayer signal collection, consolidation and analysis to achieve its goals as well as to inform and recommend better design for superior performance and better governance to match business goals.”
An effective data observability solution combines a variety of data quality and insight capabilities to develop a semantic understanding of the underlying data within an enterprise. This is done through continuous insights into data pipelines, users, activity, and compute functionality, which deliver data visibility, identify and prevent issues, and ensure that an organization’s data stack is accurate and reliable.
With deep visibility and accompanying insights about their data, data pipelines, and overall data investments, an enterprise can operate with confidence that they are using data intelligently to make smart decisions and that they’re achieving maximum ROI from their data investments. Without it, they are flying blind.
New Approaches to Managing Data
Despite the implementation of new tools and platforms, and increasing investment in engineering and operations, the majority of enterprise data teams still face significant challenges in dealing with daily operational issues. This is exacerbated by the ever-growing volume of data, complex data pipelines, and emerging technologies that place a strain on the capabilities of data teams and negatively impact the value of data systems.
Data Observability has emerged to address this new reality of unprecedented data complexity. Building upon the foundation of application performance monitoring (APM), Data Observability provides a systematic approach to monitoring and correlating data events across application, data, and infrastructure layers. This approach empowers data engineers, data architects, site reliability engineers, and data executives to detect, predict, prevent, and resolve issues, often in an automated fashion.
“Data observability is the ability of an organization to have a broad visibility of its data landscape and multilayer data dependencies (like data pipelines, data infrastructure, data applications)...” - Gartner
The rapid adoption of Data Observability is attributable to the fact that enterprises now recognize the need to ensure the accuracy, validity, and reliability of their data. Data teams see Data Observability as a foundational component of their data strategy because, among other things, it provides:
Monitoring Data Health
Monitoring and correlating data events across application, data, and infrastructure layers, providing a systematic approach to managing complex data systems.
Early Detection of Issues
Data Observability helps in the early identification, prediction, and prevention of issues, which helps avoid costly disruptions to production analytics and AI.
Automates Resolution
It allows automation of issue resolution, which saves time and resources for data teams allowing them to focus on more strategic initiatives.
Holistic View of Data System
Data Observability offers a comprehensive view of the entire data system, which helps identify areas for optimization and improvement.
Improves Coordination Among Data Teams
Data Observability provides data architects, data engineers, DevOps, site reliability engineers, and data executives with the ability to work together to address issues and optimize performance, creating a more collaborative and efficient work environment.
Boosts Data Reliability
It offers a way to identify and address issues before they impact the business, improving overall data system reliability.
Enhances Data Management
Data Observability improves the management and optimization of massive amounts of data generated by modern technologies and systems.
The Evolution of Data Observability
Identifying and understanding what’s going on in a data environment has its roots in the concepts of observability, which involves monitoring and maintaining large, but simple, application environments.
Observability, as it applies to IT environments, has been around since the 1960s and was originally developed for systems dealing with very few data sources. The concept of observability was developed by Hungarian-American scientist Rudolf Kálmán, who defined it as the ability to measure the internal states of a system through external outputs.
This definition formed the basis for control theory, which underpinned the field of systems management. In those early days, the idea was to basically ensure homeostasis among the different resources operating in an organization’s tech stack. When any type of behavior was anomalous, it was flagged.
As IT environments became more complex and relied on data being integrated from multiple applications, observability methodologies gave way to application performance monitoring (APM) solutions. This was a result of the rapid proliferation of use case-specific applications that emerged with the advent of the internet.
Data Observability was originally developed as a subset of observability, especially because of its emphasis on data reliability and operational performance for data pipelines, databases and data warehouses, but this is no longer accurate. Although they share some similarities in methodology, Data Observability tools provide a much deeper level of visibility, control, and optimization capabilities for real-time analytics and AI applications compared to legacy observability tools and APM solutions.
Look at it this way: If you were managing an organization’s IT environment during the early days of internet adoption, you would likely have thought about observability in the context of emerging IT operations management (ITOM) tools, like IBM Tivoli and Microsoft System Center, which were developed in response to the shift from mainframe to client-server computing and the rise of the internet.
They allowed for monitoring, managing, configuring, and securing data centers. The latest generation of APM tools, such as Dynatrace, AppDynamics, and New Relic, emerged with cloud computing in the last decade, claiming to offer end-to-end observability using big data and machine learning.
Data Observability is a continuation of the observability tradition in IT, with a focus on the needs of modern data-driven digital enterprises. These businesses require real-time analytics, citizen development, self-service analytics, machine learning, and AI.
Data Observability platforms are designed to provide visibility, control, and optimization of distributed and diverse data infrastructures, including legacy on-premise database clusters and data warehouses, cloud-hosted open-source data clusters, and real-time data streams.
Why is Data Observability Important?
In the past, data engineers were often considered as the "nerds" of a company. However, today, data scientists, analysts, and business intelligence professionals have experienced a transformation, gaining hero status with their ability to deliver near real-time analyses and uncannily accurate predictions that help businesses make better decisions, reduce risks, and increase revenue.
To support these data professionals and their goals, companies have invested millions in advanced data warehouses, big data analytics tools, and a variety of other solutions that are all loaded with features. Despite this investment, data engineers still face significant pain points in their job, and ironically, they all relate to the same thing: data.
Specifically, data teams consistently struggle with some recurring issues, including:
Locating appropriate data sets
Ensuring the reliability of the data in their environment
Managing continuously changing data volumes and structures
Dealing with shifting outcomes and predictions due to changing data
Lacking visibility while executing models, jobs, and SQL queries
Overcoming challenges to maintain high operational performance
Cost overruns, poor spending forecasting, and budget tracking
A starting point for data teams is to improve the overall reliability of the enterprise data they work with. Data reliability is a crucial aspect of Data Observability for data engineers because it enables them and other data team members to identify and address potential issues that could impact the desired business outcomes. Bad data that goes undetected delivers erroneous information which unwittingly gets used for important decision-making.
Unfortunately, reliability issues are common due to the vast amounts of unstructured external data that are being ingested into modern data repositories. According to Gartner, poor data quality, including data drift and other issues, costs organizations an average of $12.9 million annually. Such issues can also wreak havoc on machine learning initiatives through data, schema, and model drift.
To address these challenges, Data Observability platforms offer powerful and automated data management capabilities that keep data engineers happy. The most effective platforms provide AI-powered data reliability, data discovery, and data optimization features that ensure data accuracy, reliability, and completeness throughout the entire data pipeline, without requiring significant effort from data scientists or engineers.
The Benefits of Data Observability
Data Observability empowers organizations to gain a comprehensive understanding of their data systems and equips them with the ability to proactively identify and address data issues in complex data scenarios, or even prevent them from occurring altogether.
Much of this stems from the awareness of the correlative effect of bad data on business outcomes. It's becoming more apparent to business leaders that bad data can seriously affect their bottom lines.
Consider the Gartner study (mentioned above) that suggests that “bad data'' costs organizations about $12.9 million annually. What’s especially surprising about that study is that almost 60% of those surveyed didn't even know the exact cost of bad data for their businesses, simply because they weren't measuring it in the first place.
The UK Government's Data Quality Hub estimates that organizations spend between 10% and 30% of their revenue addressing data quality issues, which can amount to hundreds of millions of dollars for multi-billion dollar companies. As far back as 2016, IBM estimated that poor data quality cost US businesses $3.1 trillion annually.
It's eye-opening to see the impact that inaccurate data can have on businesses, and it's crucial for organizations to start taking data quality seriously to avoid these losses.
Data Observability is not limited to data monitoring. It provides enterprises with an overall understanding of their data sources and systems, which allows them to repair complicated data situations or even prevent them from occurring. Here are some of the primary benefits of data observability.
Improves Data Accuracy
By implementing effective Data Observability practices, businesses can enhance the reliability, accuracy, and trustworthiness of their data. This, in turn, allows organizations to confidently rely on data-driven insights and machine learning algorithms for making informed decisions and developing highly usable data products. However, it is important to acknowledge that inaccurate and mismanaged data can have severe consequences, undermining the integrity and reliability of business operations.
Therefore, adopting a proactive and holistic approach to Data Observability is crucial for organizations to ensure the accuracy, integrity, and reliability of their data systems. By investing in Data Observability, businesses can mitigate risks associated with data issues and unlock the full potential of their data for driving successful outcomes.
Identify and Address Data Concerns in the Early Stage
As companies become increasingly data-driven and rely on data to inform key business decisions, the importance of reliable data cannot be overstated. Access to data is critical, but ensuring its reliability is mission-critical.
While data quality monitoring tools have traditionally been seen as the solution, the shift towards distributed, cloud-centric data infrastructures has rendered them outdated. These tools were designed for earlier application environments and are unable to scale or prevent future data quality issues, making them too labor-intensive and slow to manage.
It's crucial to understand why data quality monitoring tools and their passive, alert-based approach are no longer effective. Instead of relying on legacy technology, forward-thinking organizations should explore enterprise Data Observability platforms purpose-built for modern data architectures. These platforms can rapidly fix and prevent data quality problems while automatically maintaining high data reliability.
Timely Delivery of Data
Delivering data on time ensures that business teams and analysts are working from fresh data to analyze real-time trends. Data Observability helps maintain the quality, consistency, and dependability of data available in the pipeline by offering businesses a deeper insight into their data ecosystem. It allows them to drill down and fix issues in the data pipeline, which in turn helps in the timely delivery of data when required.
Prevent Data Downtime
Data observability allows enterprises to fix issues in complex data scenarios. It helps them identify situations before they have a huge impact on the business. Data observability can provide relevant information and context for root cause analysis, which in turn helps to avoid data downtime.
Data decision-makers have prioritized Data Observability as an essential, and foundational, piece of their data environment. The Data Observability platforms they use need to be able to orchestrate critical use case elements into a single solution that helps them address the most important factors in using data to improve business decision-making.
Effective Cost Optimization
Data Observability offers analytics from data pipelines and processing which can be used for better resource planning. It can help to eliminate or consolidate redundant data, misconfiguration, and overprovisioning which can lead to better resource utilization. Moreover, it can help enterprises optimize their budget for data investments by comparing costs across different data pipelines.
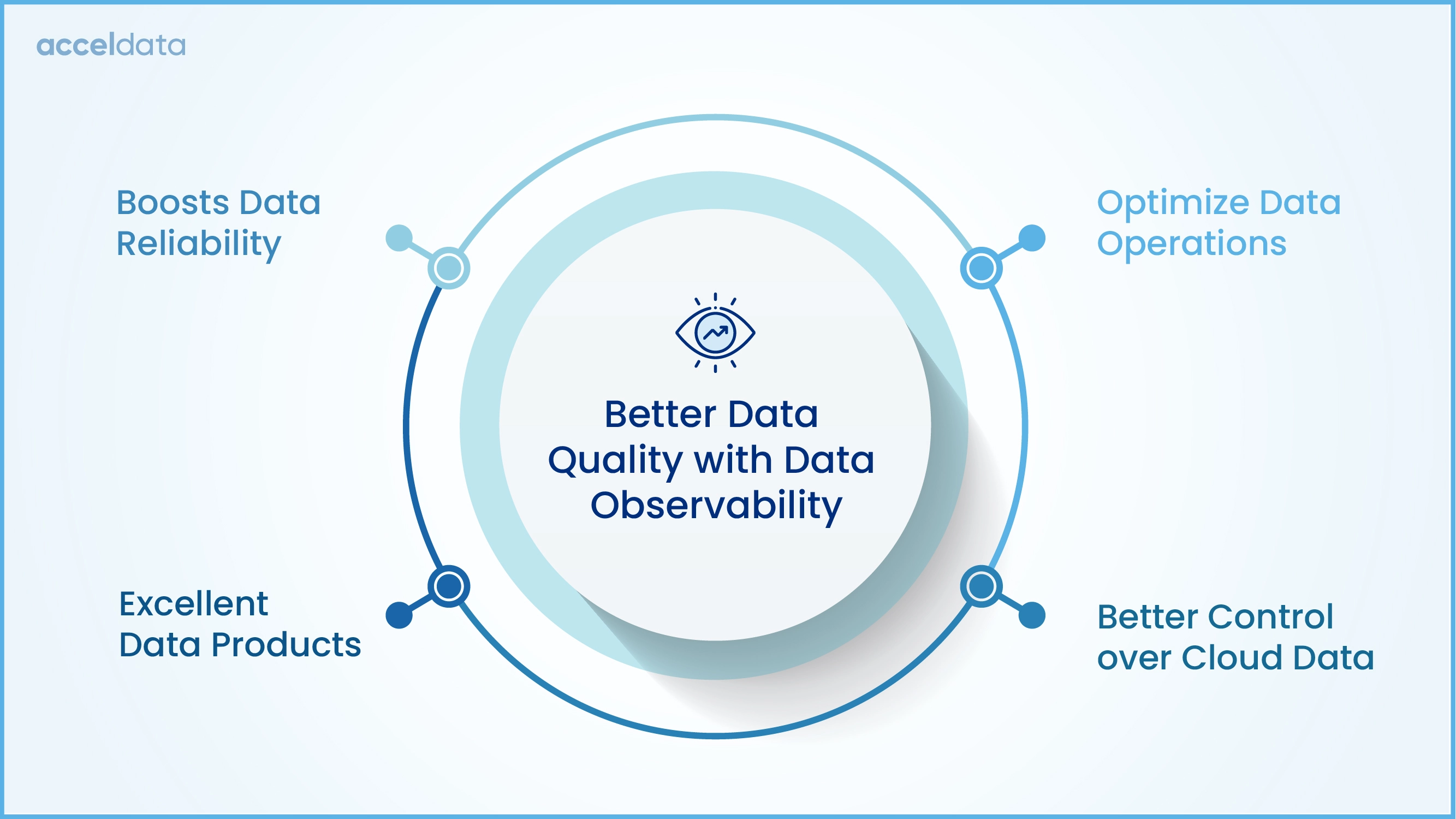
Ensure Better Data Quality with Data Observability
Incomplete data creates potential loopholes in the analytics, leading to low trust in data and poor decisions. Data observability helps to constantly monitor and measure data quality and completeness, contributing to better data quality. It provides a 360-degree view of the data ecosystem, allowing enterprises to resolve issues that can cause breakdowns in pipelines, which can ensure the consistency, reliability, and quality of data in pipelines.
Below mentioned are the ways, how data observability can help to ensure improved data quality across the system.
Boost Data Reliability with Data Observability
Modern data reliability goes beyond traditional data quality, providing data teams with complete visibility into their data assets, pipelines, and processes necessary to make data products successful. This includes advanced monitoring techniques like data cadence, data-drift, schema-drift, and data reconciliation, as well as real-time alerts and continuous processing of data policies as data changes and flows through pipelines.
Data reliability offers 360-degree insights about what is happening with data processes and provides the context to remediate problems, and scalable processing of data rules and policies to cover the ever-increasing data volumes flowing through pipelines.
Data reliability is applied at all stages of a data pipeline across data-at-rest, data-in-motion, and data-for-consumption, rather than just at the end of data pipelines for consumption.
Adopting a "shift-left" approach to data reliability allows problems to be detected and isolated early in data pipelines before they hit downstream data-for-consumption and the data warehouse. Early detection also allows teams to be alerted to data incidents and remediate problems quickly and efficiently.
Advanced monitoring, detection, and remediation techniques that include data cadence, data drift, schema drift, and data reconciliation.
Real-time alerts and continuous processing of data policies that adapt to changes and flows in data pipelines.
Comprehensive insights into data processes that enable effective problem-solving.
Scalable processing of data rules and policies to handle the growing volumes of data flowing through pipelines.
Data Observability Optimizes Data Operations
To implement operational intelligence, you first need to identify the data sources that you want to monitor. These sources can include various components, such as distributed file systems, NoSQL databases, SQL data warehouses, analytics engines, query optimizers, resource managers, event streaming platforms, and data flow platforms.
Data Observability helps to ensure operational intelligence. It works by monitoring the data flowing through complex pipelines and collecting performance information about individual and interconnected components at the infrastructure, data, and application layers based on user-defined metrics.
By using operational intelligence, you can achieve the following benefits:
Ensure reliable data: By predicting and preventing issues before they occur, you can transition from resolving and troubleshooting incidents to ensuring reliable data.
Scale effectively: You can analyze workloads, identify bottlenecks, optimize configurations, and improve performance quickly. Additionally, you can run simulation models to forecast future capacity needs, which helps you scale effectively.
Optimize resources: You can optimize resources by boosting capacity with job scheduling optimization, managing the cost of inefficient jobs, fixing hotspots, and offloading cold data to lower-cost storage options.
These benefits allow you to simplify IT operations, accelerate innovation, and lower the total cost of ownership across your distributed data landscape.
Build Great Data Products with Data Observability
Enterprise data yield actionable insights and understanding, which modern businesses leverage to make informed decisions. By analyzing vast amounts of data from various sources such as customer transactions, social media, and sensor data, companies can identify patterns and trends to inform strategic and tactical decisions around data product development, marketing, and customer service.
These data insights serve as the foundation for building great data products because they offer a better understanding of an organization's data and how it can be used to address specific business challenges. Insights can also help identify patterns and relationships within the data to inform the design and development of data products while guiding decision-making throughout the product development process.
However, with modern data stacks becoming increasingly complex, building reliable data products requires the ability to anticipate and deal with potential points of failure. Data teams must have access to trusted, high-quality data to ensure accuracy, and that means being able to investigate pipeline errors by looking at log events and metadata.
Data Observability is critical for delivering the fundamental data insights required to build data products successfully. By providing continuous transparency to all data activity, it allows data teams to monitor data quality, identify bottlenecks and performance issues, and track the quality of data to ensure its reliability and accuracy. Through Data Observability, data teams can optimize data pipelines, improve performance, and reduce latency, making it an indispensable tool for any modern enterprise looking to harness the power of its data.
Data Observability Helps to Achieve Control Over Cloud Data Costs
It's surprising to learn that many organizations report exceeding their public cloud spending budgets by 13%, and expect this excess spending to increase by 29% by the end of 2022. While one might assume this is due to the sheer volume of data being stored and processed, the reality is that these organizations waste approximately 32% of their cloud spending.
So, why are businesses overspending, and how can this be addressed? The solution lies in implementing effective Data Observability practices within the organization to improve cloud costs and optimize your data warehouse spend.
These are some ways that data teams use Data Observability to optimize their cloud data costs:
Real-time Monitoring
Data Observability allows you to monitor your cloud data operations in real-time, providing you with insights into the cost implications of different data processes. By continuously monitoring your data pipelines, storage usage, and data processing jobs, you can identify any anomalies or cost inefficiencies early on and take corrective actions promptly.
Cost Attribution
Data Observability can help you track and attribute costs to specific data sources, data pipelines, or data processing jobs. This visibility enables you to understand the cost drivers and allocate resources efficiently. With clear cost attribution, you can identify data operations that are contributing to high cloud costs and optimize them accordingly.
Data Quality Assurance
Data Observability also ensures that the data being processed in the cloud is accurate, complete, and of high quality. By identifying and addressing data quality issues in real time, you can prevent unnecessary cloud costs resulting from processing erroneous or incomplete data. This helps in reducing reprocessing costs and improves overall cloud cost efficiency.
Resource Optimization
With Data Observability, you can identify underutilized or overutilized cloud resources, such as storage or computing instances, and optimize their usage. By analyzing data usage patterns and resource utilization metrics, you can right-size your cloud resources, reduce unnecessary costs, and improve cost efficiency.
Cost Prediction and Forecasting
Data Observability can also provide predictive analytics capabilities that allow you to forecast and estimate future data processing requirements and associated costs. This helps in proactive cost planning, budgeting, and resource allocation, ensuring that you have better control over your cloud costs.
Automation and Alerts
Data Observability tools can automate the monitoring and detection of cost-related anomalies, generating alerts or notifications when unexpected cost spikes or deviations occur. This enables you to quickly respond to cost-related issues and take necessary actions to mitigate them, resulting in better cloud cost control.
Data Observability vs. Data Monitoring
Data monitoring involves the continuous monitoring of data flow and system performance to ensure compliance with specifications and SLAs. It typically includes setting thresholds and alerts to detect issues like bottlenecks or data loss.
On the other hand, Data Observability encompasses understanding the internal state of a system by collecting and analyzing data from various sources, such as metrics, traces, logs, and real-time data access and querying. An enterprise Data Observability platform goes beyond comprehensive monitoring and ensures that data, data systems, and data quality are monitored from all angles, without neglecting any crucial aspect. It assumes that data is constantly in motion, and thus continuously discovers and profiles data wherever it resides or travels through data pipelines, avoiding data silos and detecting early signs of data quality degradation.
Additionally, Data Observability platforms utilize machine learning to combine and analyze historical and current metadata from various sources to gain insights into data quality.
Data Observability allows for tracking data as it flows through data pipelines, identifying and addressing issues or inconsistencies that may impact data quality. This enables timely detection and resolution of problems, in contrast to data monitoring that relies solely on threshold-based alerts, which may not provide early warnings for recovery.
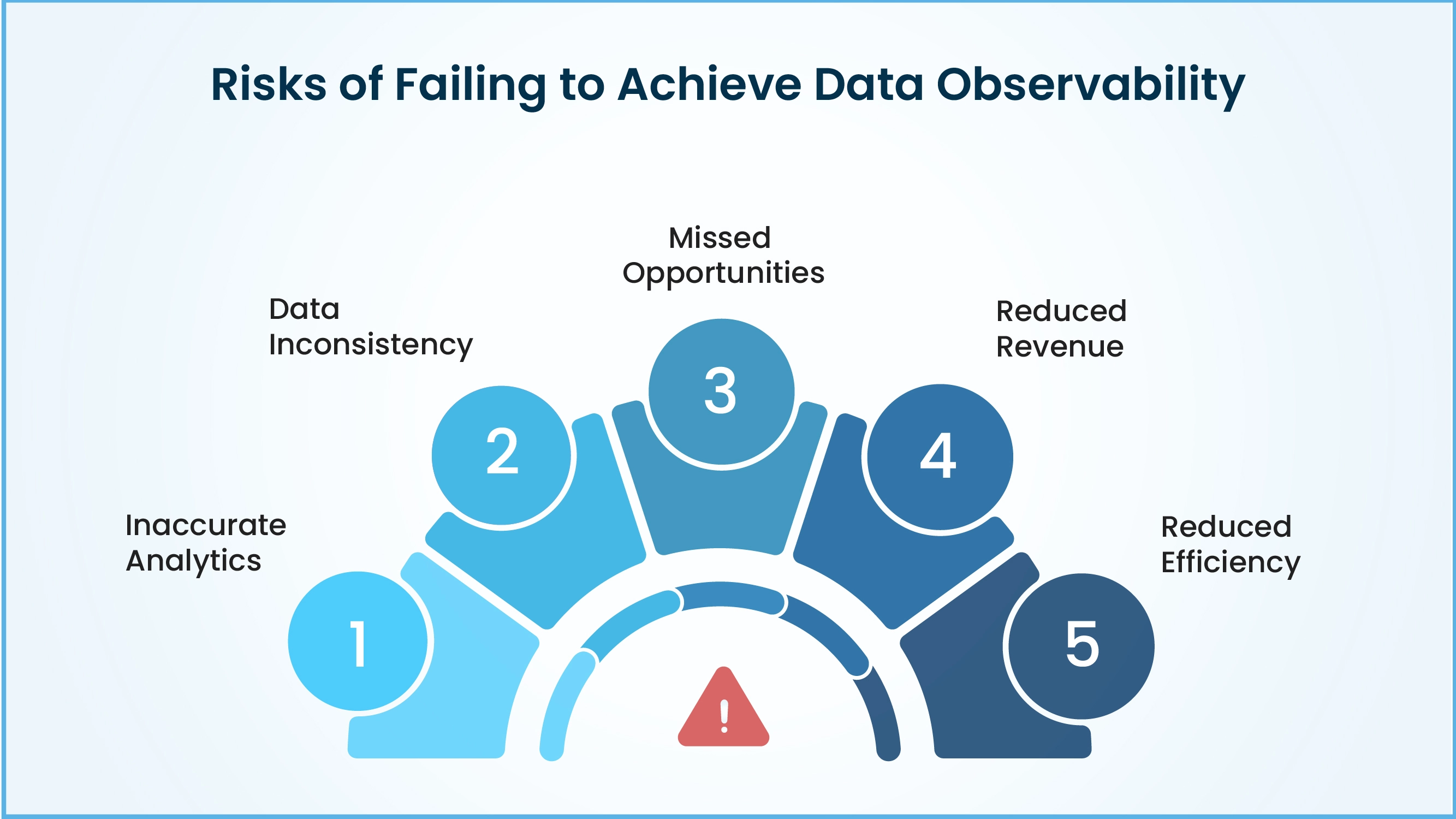
Risks of Failing to Achieve Data Observability
Everyone knows the old adage, “garbage in, garbage out.” It’s not just a pithy anecdote; the reality is that not having continuous, comprehensive awareness of how your data is being used, where it comes from, how it integrates with other data, how it’s moved in pipelines, and how much it costs to manage can create major operational and economic issues for enterprises.
The bottom line is that ignoring data quality can have serious consequences that can hinder your business growth. Without the benefits of Data Observability, enterprises are unable to optimize, much less manage, their data and will suffer from these risks:
Reduced Efficiency
Poor data quality can hinder the timeliness of your data consumption and decision-making, resulting in reduced efficiency. In fact, studies show that the cost of poor data quality to the US economy could be as much as $3 trillion in GDP. To leverage data effectively, it's crucial to use tools and processes that optimize your time and resources, allowing you to focus on strategic initiatives throughout the fiscal year. Otherwise, valuable time and energy may be wasted on managing data quality issues and correcting avoidable mistakes instead of making informed decisions to drive business growth.
Missed Opportunities
Without Data Observability, organizations face reliability issues that prevent them from delivering effective data products to both customers and external stakeholders, leading to missed opportunities.
A data product refers to a product or service that utilizes data to deliver valuable insights or information to its users and can encompass anything that aids in data-driven decision-making. Data products are typically designed for specific user groups within specialized fields, such as healthcare professionals, brokers/traders, or product designers, and are tailored to address specific problems or use cases.
Unreliable data leads to inefficient or inaccurate data in these types of products, which is a killer for users and results in missed opportunities to engage and develop incremental revenue channels. By prioritizing data reliability, emphasizing data cost optimization, and having operational intelligence across your entire data stack, you can avoid missed opportunities, develop quality data products, and build strong customer relationships.
Reduced Revenue
Flawed data can directly impact your revenue. If data teams cannot see where data is being used and how they’re being charged for consumption, they will likely see major cost overruns and misallocation of charges.
Without spend intelligence provided by Data Observability, companies will see unexpected cost spikes in their data usage which are caused by prolonged jobs and queries. As data teams dig deeper to determine the underlying causes of these unusual patterns, they’ll uncover missing or poorly configured safeguards that failed to prevent these costly unintentional errors.
With Data Observability, these teams can identify potential vulnerabilities that could impact their data costs. They also make necessary adjustments with automated safeguards and configurations in the observability platform that will prevent future incidents and ensure optimal performance of their data environment.
Types of Data Observability
As you can see, Data Observability covers a lot of ground, and each of its various elements provides essential benefits to a data-driven organization. Keep in mind that there are different types of Data Observability, or rather, there are various approaches to achieving and maintaining a healthy data environment. These focus on different aspects of the data stack, but they are when combined, a powerful force. They include:
Analysis of Independent Data
Analyzing data independently, without considering any other data dependencies, can reveal broader data issues beyond general accuracy and completeness. Solutions can focus on testing and monitoring data using unsupervised algorithms to identify metrics, anomalies, and outliers. These solutions keep track of data and associated metadata, and alert for any changes in historical patterns. This approach can be implemented both top-down, driven by context, and bottom-up, through data patterns, data fingerprinting, and inferences from data values.
Data Environment and Infrastructure Observability
In addition, certain solutions are exploring the integration of signals and metrics from the data infrastructure layer as a crucial component of the overall data life cycle. These solutions aim to capture logs and metrics related to resource consumption, such as compute, performance, under-provisioning, and over-provisioning of resources, which can be utilized for cost optimization strategies like FinOps and cloud governance. Additionally, these solutions monitor and analyze logs and operational metadata from query logs in the processing layer.
Data Users Analysis
Data Observability caters to advanced roles such as data engineers, data scientists, and analytics engineers. The challenges mentioned earlier are primarily related to data delivery, service level agreements (SLAs), and pipeline design. Data Observability focuses on predicting and preventing these issues before they occur, leveraging additional metadata analysis and activation. These challenges are often beyond the scope of business users, data quality analysts, or business stewards, as they are more upstream concerns. If these issues make it to production systems, significant damage may already have occurred.
Data Observability tools are particularly well-suited for streaming and real-time data requirements, as traditional data quality monitoring tools are limited in their ability to profile and understand data characteristics. This underscores the clear need for solutions that can rapidly observe and identify issues in streaming data scenarios.
Data Pipeline Awareness
Issues related to data pipelines, transformations, events, applications, and code that interact with data can be identified by observing data-pipeline-related metrics and metadata. Any deviations in volume, behavior, frequency, or other expected or predicted behaviors from the data pipeline metrics and metadata can be considered anomalies, and alerts can be triggered based on change detections.
Why Are Data Teams Using Data Observability?
Establishing effective data reliability and operational intelligence can be difficult to implement and maintain. The challenges that many enterprises face with implementing Data Observability stem from lingering issues that include data quality and data lineage issues with the data stack (this includes the user, compute and infrastructure, data reliability, and data pipeline elements of the data stack). The goal is to create an environment that is ensuring that data is accurate, complete, and reliable.
“To improve the success of data and analytic initiatives, enterprises must address underlying data problems such as data silos, inaccessible data/analytics, and excessive reliance on manual interventions…” - Gartner
Lack of a unified view of the entire data lifecycle can lead to inconsistencies that can significantly impact data quality. Moreover, there is a paradox where enterprises are collecting, storing, and analyzing more data than ever before, but the cost and expertise required for processing and analysis are also increasing.
Consequently, data and analytic capabilities are not easily accessible for consumption and analysis throughout the organization. Only a limited number of individuals with the necessary skills and access are able to utilize small portions of the data, resulting in enterprises not fully realizing the potential value of their data.
Simply collecting more data does not guarantee better analytics and insights. According to Gartner, only 20% of data and analytics efforts are expected to result in real business outcomes. To improve the success of data and analytic initiatives, enterprises must address underlying data problems such as data silos, inaccessible data/analytics, and excessive reliance on manual interventions.
To achieve successful data operations, data teams need to go beyond basic data cleaning of incomplete or duplicate records. A comprehensive Data Observability solution addresses these challenges by breaking down data silos, making data analytics accessible across the organization, and driving better business outcomes.
Additionally, some Data Observability solutions leverage AI for advanced data cleaning and automatic detection of anomalies, empowering data teams to leverage the power of artificial intelligence in their data analytics efforts.
The Future of Data Observability
To successfully implement Data Observability, data decision-makers must prioritize requirements and select a comprehensive Data Observability product that minimizes the need for custom integration work. Beginning with small, achievable observability projects, cross-functional teams of contributors should focus on addressing key pain points, such as performance and efficiency. Early successes can pave the way for more ambitious observability efforts, provided that business and IT leaders continue to replace and retire outdated tools.
While there is not yet a Gartner magic quadrant for Data Observability, Gartner featured Data Observability in their 2022 Data Management Hype Cycle and has said this about the category: “Data observability has now become essential to support as well as augment existing and modern data management architectures”.
Data Observability is becoming increasingly important as organizations rely more on data-driven decision-making processes. In the future, we can expect Data Observability to continue to play a critical role in ensuring data accuracy, reliability, and consistency across an organization's various data sources.
Some potential developments in the future of Data Observability include:
Increased Automation
As data volumes continue to grow, it will become increasingly challenging for humans to manually monitor and observe all data sources. We can expect to see more automation in Data Observability processes, including automated anomaly detection and alerting.
Integration with Machine Learning
Machine learning algorithms can help identify patterns and anomalies in data, which can be used to improve Data Observability. In the future, we can expect to see more integration between Data Observability tools and machine learning models.
Greater Emphasis on Data Lineage
Understanding the lineage of data is essential for ensuring its accuracy and reliability. In the future, we can expect to see more emphasis on tracking and visualizing data lineage to help identify data quality issues and ensure data consistency.
Expansion Beyond Data Engineering
While Data Observability has traditionally been a concern for data engineering teams, we can expect to see more stakeholders becoming involved in Data Observability. This could include data scientists, business analysts, and even executives who rely on data for decision-making.
Overall, the future of Data Observability is likely to involve greater automation, integration with machine learning, and broader stakeholder involvement. As data continues to play a critical role in organizations, Data Observability will become even more important for ensuring the accuracy and reliability of data-driven decision-making processes.
Enhance Your Organization’s Data Reliability with Acceldata Data Observability
When data is done right, it can help enterprises drive outsized financial performance. Data is one of the primary drivers for incredible profitability and growth. In order to ensure the availability of error-free and high-quality data, a data observability tool is a must.
These tools are the first step to creating, operating, and optimizing data systems that utilize a large amount of data to improve performance, make informed business decisions, and attain competitive advantage.
Acceldata’s data observability platform can support your ability to create and operate a productive data infrastructure. It empowers data teams with valuable insights into spend, data reliability, and pipelines.
NEW REPORT
Gartner® Report: How to Evaluate AI Data Readiness









































.svg)