







































.svg)





New

Explore the future of AI-Native Data Management at Autonomous 26 | May 19 --> Save your spot

Everything you need to build, govern, and scale data and AI workloads—one unified platform.


Monitor, detect, and resolve data and AI issues with end-to-end observability across pipelines.
Build, orchestrate, and run data pipelines with intelligent agents that automate the entire engineering workflow.
Query your lakehouse in-place with Velox-accelerated performance. 10x faster than traditional warehouses.






Distributed training, high-throughput inference, and GPU notebooks—everything you need for production AI.






Build, deploy, and manage intelligent agents to automate and optimize data operations.

Browse solutions to help you solve the complex business challenges unique to your industry.
Browse materials to help you access the tools, guides, and insights essential to your workflows.
Learn about our mission, leadership, and vision driving modern data operations forward.


Browse solutions to help you solve the complex business challenges unique to your industry.
Browse materials to help you access the tools, guides, and insights essential to your workflows.
Learn about our mission, leadership, and vision driving modern data operations forward.
Everything you need to build, govern, and scale data and AI workloads—one unified platform.
Monitor, detect, and resolve data and AI issues with end-to-end observability across pipelines.
Build, deploy, and manage intelligent agents to automate and optimize data operations.
Build, orchestrate, and run data pipelines with intelligent agents that automate the entire engineering workflow.
Query your lakehouse in-place with Velox-accelerated performance. 10x faster than traditional warehouses.
Distributed training, high-throughput inference, and GPU notebooks—everything you need for production AI.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin mi
Monitor, detect, and resolve data issues with end-to-end observability across pipelines.
Monitor, detect, and resolve data issues with end-to-end observability across pipelines.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin mi nibh
AI-powered observability and optimization for Hadoop and big data environments.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse so
An open-source data platform for Hadoop modernization, flexibility, and long-term control.
.webp)
.png)
.png)











No more sampling, no cutting corners on DQ rules. Acceldata platform dynamically scales to measure the quality of all your critical data assets against all the rules and business policies needed to ensure data trust.





Yes, we monitor both data in the could and on-premises. For data on premises, our data plane can be deployed within your environment. The data plane sends only meta data back to the control plane. None of actual data ever leaves your premises. Read more about the platform architecture here.
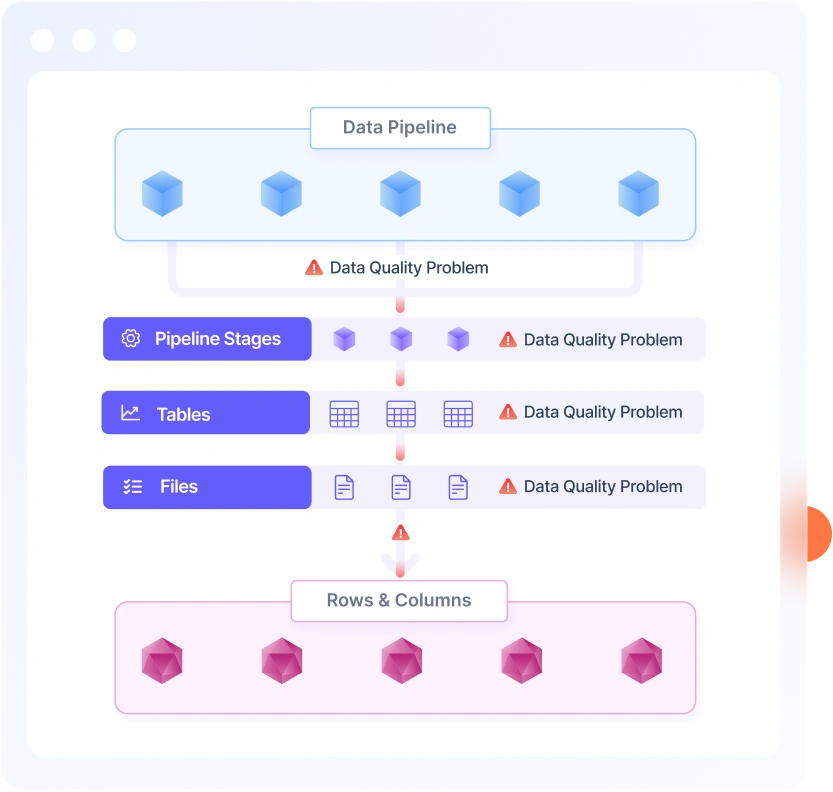
In addition to traditional Data Quality, we monitor data drift, schema drift, data freshness, reconciliation of data across data hops. These and other monitors provide you a comprehensive health of your data.
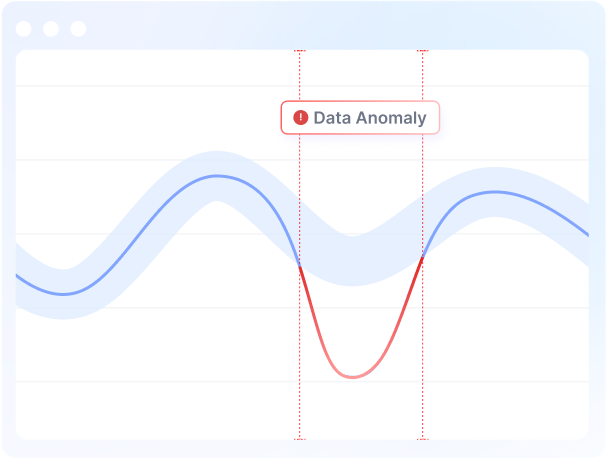
Acceldata’s Anomaly detection algorithm is extremely sophisticated and built entirely on your data set, hence the accuracy of alerts is extremely high. In addition anomaly detection has sensitivity levels (low, medium and high), which can be used to minimize anomalies.
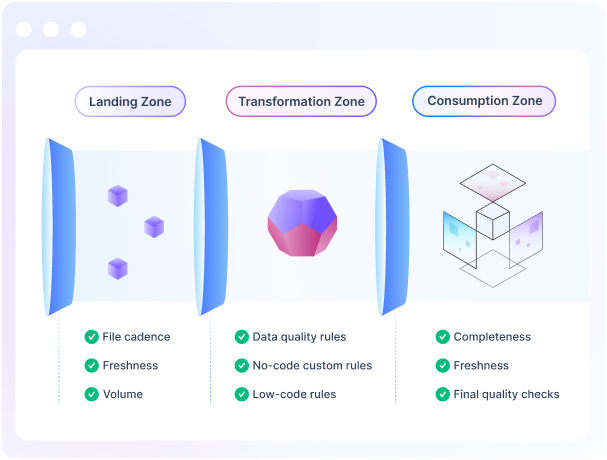
We have a three tier approach. Based on AI based detection of asset type and field a basic set of Data Quality policies are automatically applied. These policies can be modified or edited. Second, we apply Anomaly detection to automatically detect drift in quality and other metrics. This is based on AI models that is built solely based on your data. Third, we allow you to write highly specific custom rules based on a no-code interface. For highly complex business specific rules, we also enable low-code rules that can be written in any language such as SQL, Python, Javascript and such.
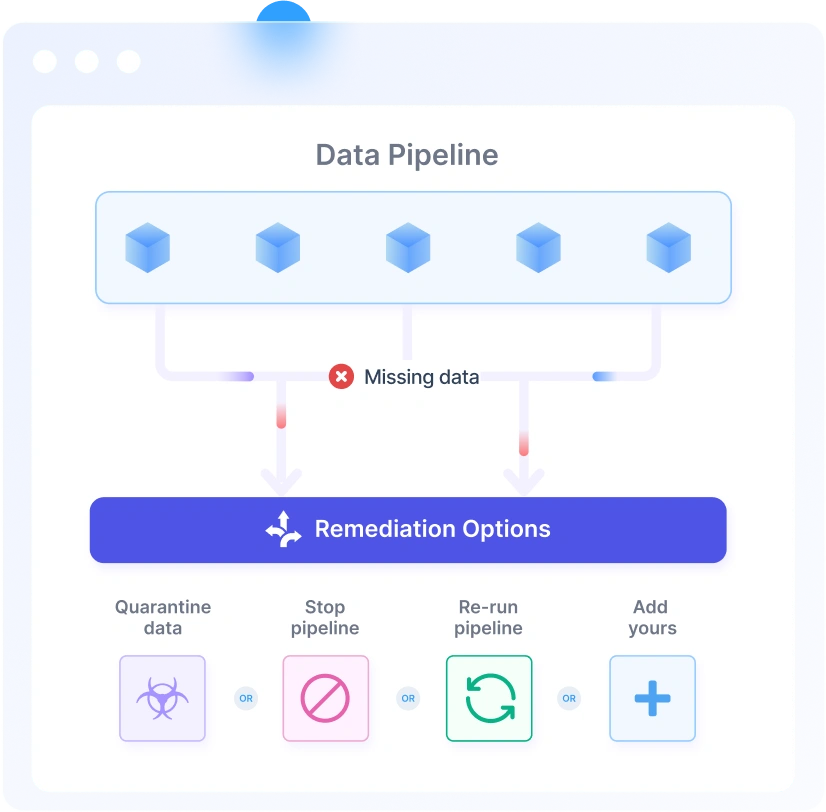
Critical data assets can be tagged and any issues from those can immediately be prioritized. You can also prioritize highly used assets for faster remediation to minimize impact to your business.





































