
























































.svg)



































.png)
Scale, Scale and More Scale
Facebook was founded at the dawn of the big data era, so it’s appropriate that the company is not only renowned for its proficiency at using big data to drive its business, but also as one of the biggest producers of data.
Back in 2014, the company revealed that its Hadoop Hive-based data warehouse alone generated more than 4 petabytes of data a day (1.5 exabytes a year). That widely-reported — and wildly-outdated — statistic did not include Facebook’s two other major analytical data stores at the time, ODS and Scuba.
More significantly, that 4 PB/day figure excluded all of the photos and videos uploaded by users to Facebook, which deletes none of them. To store them cost-effectively, Facebook in 2013 began building the first of many exabyte-sized data centers for cold storage. Facebook now has a network of seventeen cold data centers. Its newest one, the Eagle Mountain Data Center in Utah, likely will store between three and twelve exabytes, according to experts.
(Read about other Big Tech companies in our series on data engineering best practices, including how LinkedIn scaled its analytical data platform to beyond one exabyte, how Netflix keep its massive data infrastructure cost-effective, and how JP Morgan Chase optimizes its data operations using a data mesh.)
Growth Created Complexity — and Waste
To accommodate all of that data, Facebook previously had three data storage infrastructures tailored for each use case:
- Haystack, for hot blob data such as new, popular photos
- f4, for storing warm/cold data blobs such as its many exabytes of archived photos
- HDFS clusters for its Hive data warehouse that way back in 2014 already managed 300 petabytes of data.
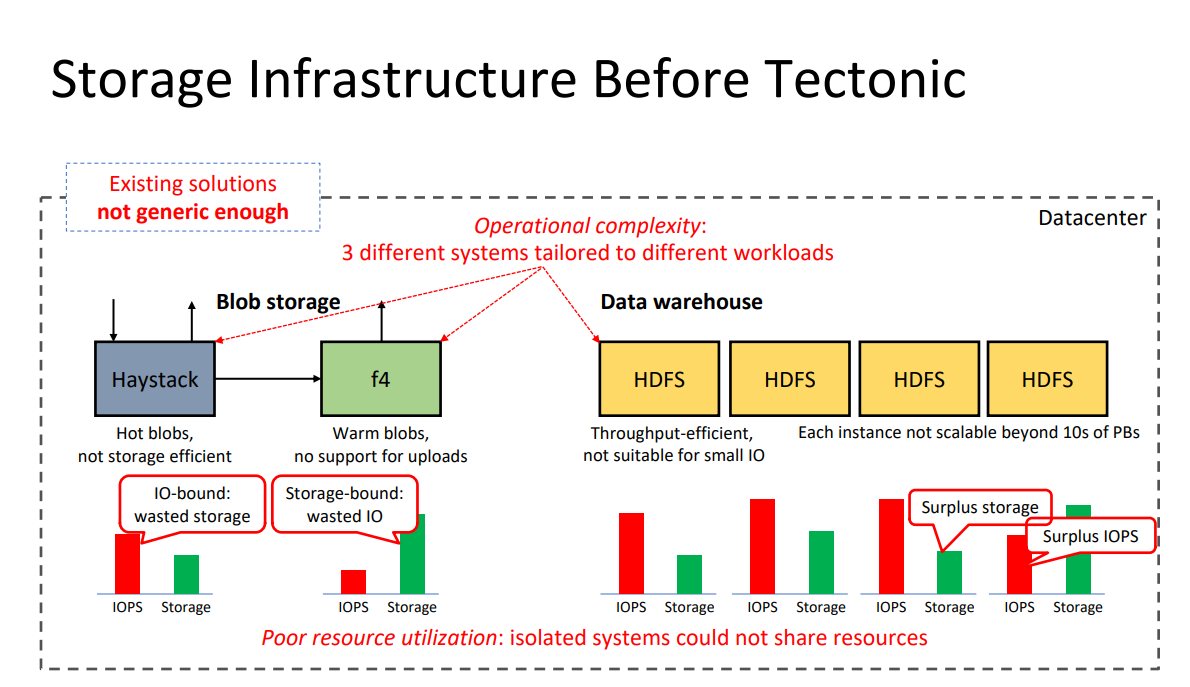
While each of these storage systems were optimized for their intended workloads, they had four significant drawbacks.
- Managing these very technically-different systems was complicated and time-consuming, creating operational complexity.
- More systems creates more wasted resources. Hot-tier storage such as Haystack, for example, requires a high number of IOs per second (IOPS) so that photos can be accessed as quickly as possible. However, hard disk speeds have not increased as quickly as disk sizes. So to achieve desired download speeds, Facebook had to make more copies of the same file. Eventually, it was forced to effectively keep basically 5 copies of every photo in order to ensure they could be accessed quickly. By contrast, once photos are moved to the f4-based archive, IOPS no longer mattered, sheer disk capacity did. But the result was an excess of unused IOPS in f4 that was stranded and wasted.
- Another drawback was age — these systems were relatively old in cloud years. Haystack had been around since at least 2009, while f4 was revealed publicly in 2014. There had been many advances in hardware, software, and design thinking since then.
- The final drawback was simply the lack of scale. While f4 had long proven its ability to store exabytes of old photos, the same could not be said about the other two storage platforms. By 2021, Facebook was storing multiple exabytes in its data warehouse, with reads in the order of multiple MBs, and writes in the tens of MBs.
There Can Be Only One
These exabyte-scale needs drove Facebook to build a next-generation storage system called Tectonic. Tectonic was first revealed publicly in a blog post, conference paper and presentation, and video in the first half of 2021.

Facebook designed Tectonic (above) to be a massive, unified file system for all of its data. That would hopefully allow it to avoid wasteful resource overprovisioning and fragmentation. It would also make Tectonic easier to manage, since all data workloads would be stored on the same file system, albeit isolated so that each tenant or workload could operate as fast or slow as needed.
Tectonic was also designed for scale. Each cluster can be multiple exabytes in size, large enough to serve an entire Facebook-sized data center. That is unlike prior generation systems, where individual clusters topped out at tens of petabytes. Larger clusters enable IOPS or storage to be shared among different workloads that would otherwise be wasted in smaller clusters. Larger, fewer clusters are also easier to manage than many smaller ones.
Designing such a system is one thing. There is an awesome amount of data engineering work needed to actually achieve such scale and high performance on demand. In the papers and presentations above, Facebook goes into technical detail to explain how it built Tectonic to achieve these goals in real life, not just on paper.
Crashing the Unified File System Party
Tectonic was also a bid by Facebook to catch up to some of its Big Tech rivals. Take Google. It pioneered the Google File System, which was introduced back in 2003 to run on inexpensive PC hardware. GFS enabled Google to build massive, reliable clusters of servers running Hadoop MapReduce to power its search engine at lower cost than buying the then dominant solution — expensive, proprietary Unix servers from Sun Microsystems and HP. Google replaced GFS in 2010 with a newer cluster-level file system called Colossus. Google confirmed in April 2021 that it continues to use Colossus to underpin all customer data stored in the Google Cloud as well as its own popular services, such as YouTube, Drive and Gmail.
Microsoft, meanwhile, created its own alternative exabyte-scale file storage system called Cosmos in 2006. Cosmos stored many exabytes of data for Microsoft services including Ad, Bing, Halo, Office, Skype, Windows and XBOX. However, unlike Google’s Colossus, Cosmos never became Microsoft’s sole file storage platform due to its lack of support for Hadoop analytics, as well as internal alternatives such as the cloud storage system, Windows Azure Storage, introduced in 2008. Microsoft has since attempted to rectify this. In 2017 it announced Cosmos’ replacement: the Azure Data Lake Store (ADLS), which provides compatibility for both Cosmos and HDFS, Hadoop’s file system, and is intended to be its unified system for all “internal big data workloads” and “an externally-available Azure service.”

Solving for Exabyte-Sized Scalability
Every Tectonic cluster is comprised of three things:
- Storage nodes (each with 36 hard drives and a 1 TB SSD cache)
- Metadata nodes that provide file directory services
- Stateless nodes for constant background operations
Each Tectonic cluster is designed to support up to ten tenants that can be a mix of blobs (i.e. photos and other multimedia) and data warehouses, and to be able to scale to serve an entire exabyte-plus Facebook data center.
The storage nodes are built around Tectonic’s Chunk Store, a flat, distributed object store that stores chunks of data that make up logical blocks that comprise files. The chunk store’s flat design is what allows it to grow to multiple exabytes.
To find a piece of data in Tectonic, a Client Library must orchestrate remote procedure calls to the metadata and storage nodes. There are three types of metadata — names, files and blocks — that are stored in the metadata server’s key-value store (called ZippyDB), and reconstructed by the stateless metadata services. Separating these layers allows them to independently scale as needed, preventing hotspots that are common with metadata servers, according to computer science professor Aleksey Charapko.
“One problem Facebook had with HDFS in their analytical cluster is limited metadata server scalability, and therefore Tectonic avoids ‘single server’ Metadata Store,” he wrote. Instead, with Tectonic “all metadata is partitioned based on some directory hashes to allow multiple metadata servers to work at the same time.”
In other words, the distributed, flexible design of Tectonic’s metadata store prevents it from becoming the bottleneck on either storage growth — each cluster can support billions of files and many exabytes of data — or file read speeds (IOPS).
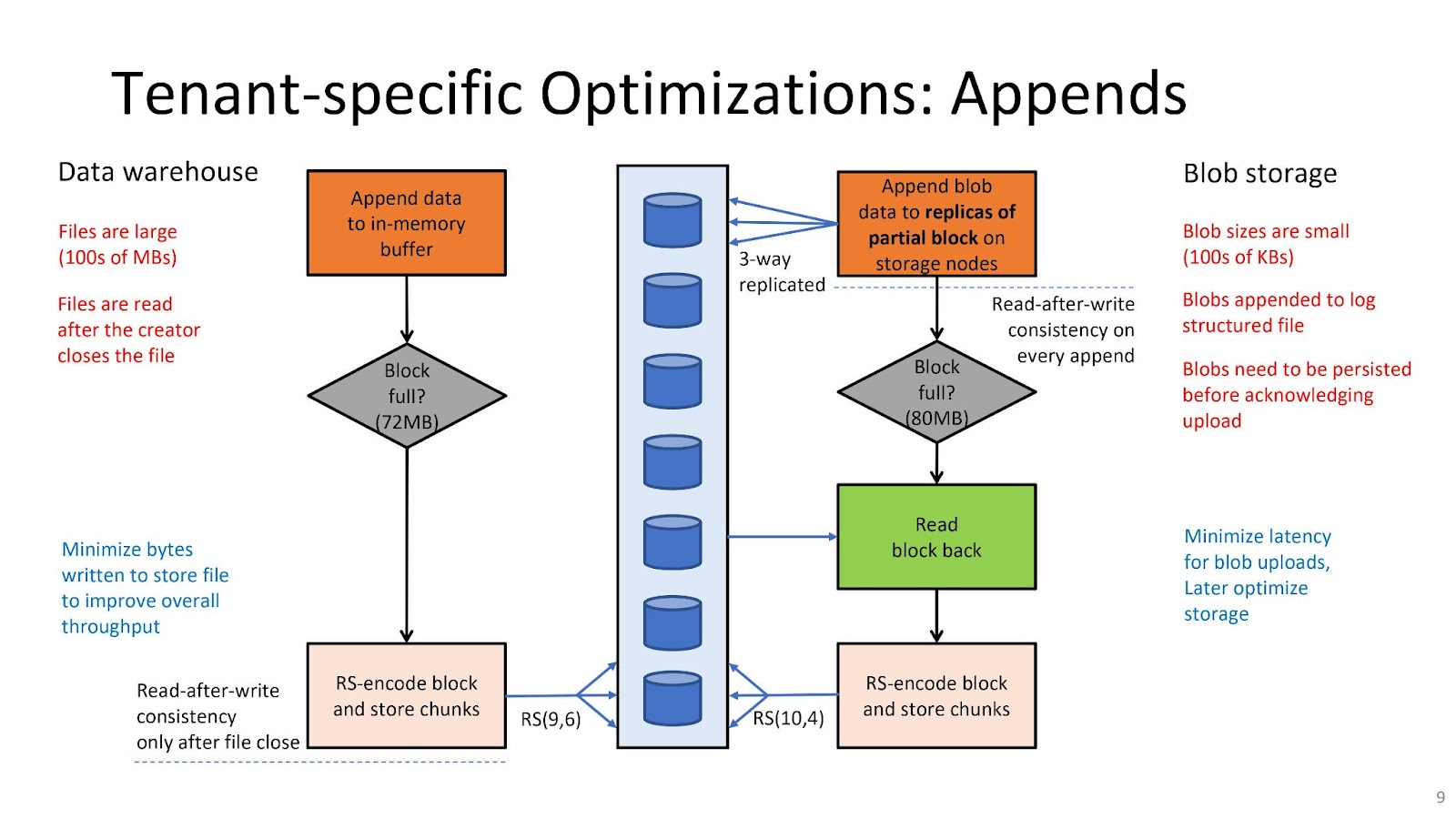
Different Speeds for Different Applications
Another aspect of Tectonic’s flexibility is its ability to shift what Facebook calls “ephemeral resources” such as IOPS and metadata query capacity between workloads on the same cluster. This resource sharing between tenants is determined by application groups called TrafficGroups. Each cluster has 50 TrafficGroups with different performance settings around latency, IOPS, etc. Tenants are responsible for choosing the right TrafficGroup to satisfy their application SLAs.
TrafficGroups may be the most important feature in Tectonic to provide the tenant-specific control and optimizations that many feared an unified file system could not provide. It enables Facebook’s data users to tweak performance needs down to the individual applications, overcoming their worries that performance would degrade as they moved from Haystack, f4, or HDFS to Tectonic.
Data warehouses can have their workloads modeled for write-once-read-many patterns, and then tailored to accelerate write times or minimize IO. Photos and other blob storage can be stored non-encoded for faster retrieval when they are new, and then re-encoded and re-written using Reed-Solomon as they age for maximum compression. For Tectonic administrators and data engineers, using TrafficGroups makes resource management for every Tectonic cluster manageable.
Cautionary Note
The end result? Tectonic’s “exabyte-scale consolidated instances enable better resource utilization, simpler services, and less operational complexity than our previous approach,” writes Facebook.
At the same time, the company is honest enough to admit that there are a “few areas where Tectonic is either less flexible or less performant than Facebook’s previous infrastructure.”
One was the higher metadata latency in the data warehouse. With HDFS clusters for data warehouses, metadata operations are performed in-memory and all metadata for a single namespace is stored on a single node. In Tectonic, this data is stored in a sharded key-value store and disaggregated over three layers. This is a more flexible design that prevents catastrophic hotspots and bottlenecks. But it is also more complex and generally slower. Certain metadata operations had to be rewritten by Facebook to avoid annoying slowdowns.
Another area was the hash partitioning of the metadata. Spreading the data among many shards means it needs to be continually refreshed to avoid it becoming stale. Still another issue was memory corruption, which Facebook says is common in large-scale systems. To prevent data that is corrupted in memory leading to corrupted data written to disk, Facebook is “enforcing checksum checks within and between process boundaries.”
While Tectonic was intended to be an unified file platform for Facebook, several services do not use it. These include software binary package deployments, which cannot have any dependencies. Also, graph databases are not using Tectonic because the latter is not yet optimized for key-value store workloads that “often need the low latencies provided by SSD storage,” according to the company.
Tectonic Today and Tomorrow
Nevertheless, Tectonic has led to a major shakeup of Facebook’s data infrastructure. In its 2021 Usenix paper, Facebook revealed that it had already been using Tectonic to “host blob storage and data warehouses in single-tenant clusters for several years, completely replacing Haystack, f4, and HDFS.”
Of course, multi-tenant clusters are a much bigger step. In its Usenix paper, Facebook detailed the successful roll out of an apparent proof-of-concept multi-tenant cluster. This cluster had 1,590 PB of total storage that was 70 percent utilized (1,250 PB) with 10.7 billion files and 15 billion blocks over 4,208 storage nodes.
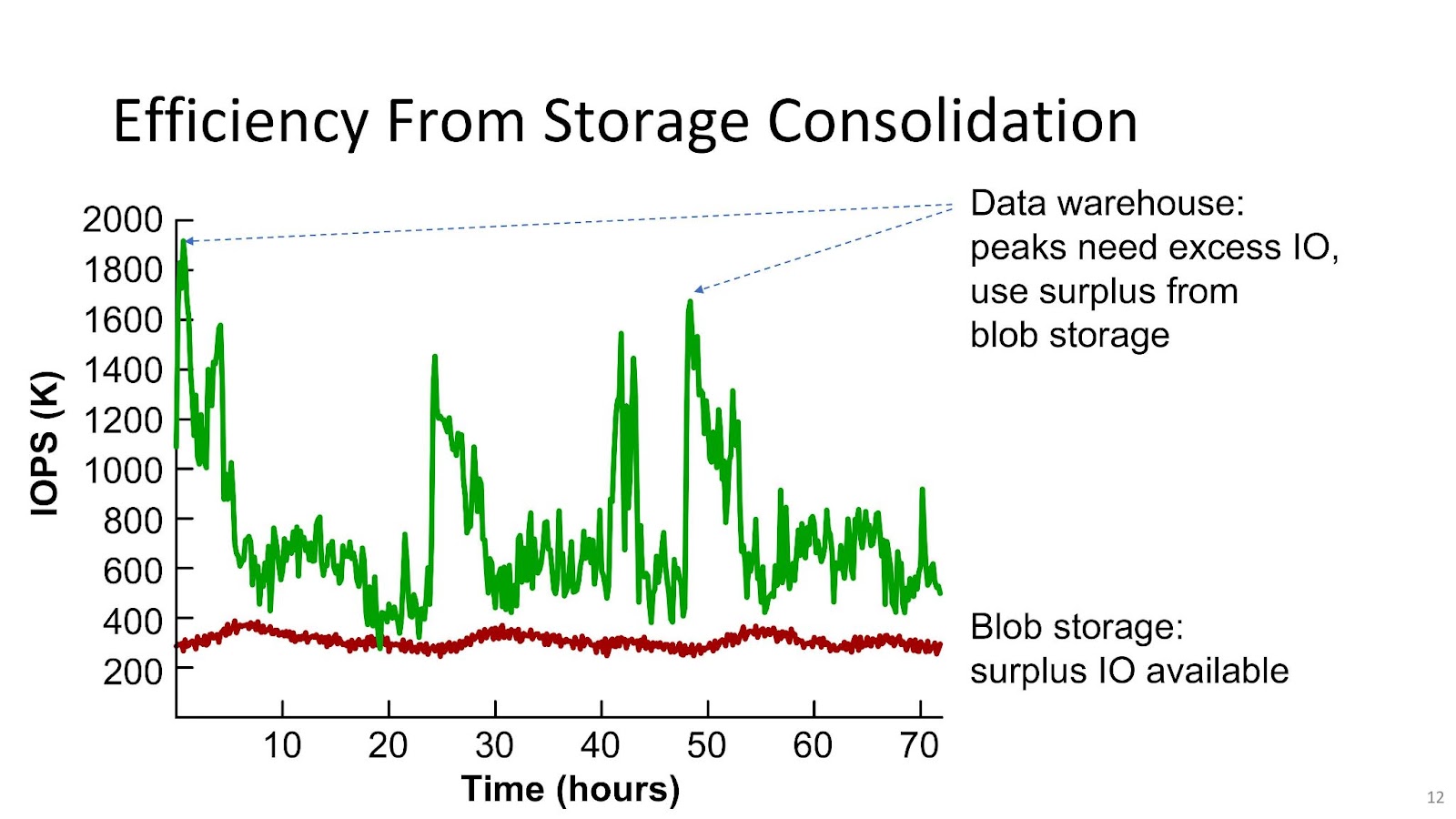
There were two tenants using equal amounts of storage: blob storage and a data warehouse. While the data warehouse had large, regular load IOPS spikes due to large batch reads of data, the blob storage traffic was smooth and predictable. This enabled Tectonic to automatically shift unused IOPS capacity from the blob tenant to the data warehouse when the latter was hit with a large analytical job.
Just as designed, the Tectonic cluster maintained satisfactory IOPS performance for the data warehouse during spikes. This allowed Facebook to avoid overprovisioning disks for the data warehouse just to satisfy occasional peak loads. This two-tenant cluster also successfully avoided metadata server hotspots that would have dragged down file and data read speeds through the flexible, independently-scalable design of the metadata store.
With that success, Facebook says “multitenant clusters are being methodically rolled out to ensure data reliability and avoid performance regressions.”
This has already “yielded many operational and efficiency improvements.” Moving data warehouses from HDFS onto Tectonic has “reduced the number of data warehouse clusters by 10x, simplifying operations from managing fewer clusters.”
Meanwhile, “consolidating blob storage and data warehouse into multitenant clusters is helping data warehouses “handle traffic spikes with spare blob storage IO capacity. Tectonic manages these efficiency improvements while providing comparable or better performance than the previous specialized storage systems.”
Data Observability Optimizes Your Data Infrastructure
Obviously, most companies lack the size and budget to warrant building their own custom unified file system like Tectonic.
There is a much easier way for most companies to achieve the scale, ease of management, and cost-efficiency of their data that Facebook sought.
Deploying a multidimensional data observability platform is a far quicker, more cost-effective, and more successful path to value engineering your data and storage infrastructure.
Acceldata’s platform offers a single pane of glass into all of your data repositories and data pipelines, no matter how far-flung or diverse.
For instance, Torch, our data quality and reliability solution, automates data discovery and cataloging on an ongoing basis. Through a centralized inventory, all datasets, regardless of where they are stored, are visible to all users in the system. This reduces unnecessary data and prevents the formation of costly data silos. It also makes data migrations less hazardous and error-prone, something Facebook obviously faced when it consolidated its file systems onto Tectonic.
Meanwhile, Acceldata Pulse assists businesses in saving millions of dollars each year by assisting them in offloading superfluous, over-provisioned software and optimizing capacity planning. Again, the same sort of resource optimization that Tectonic delivers, but at the scale your company needs, and delivered in a turnkey fashion.
Request a demo to learn more about how Acceldata can assist your company gain the unified ease of management, low ops and resource optimization of Facebook Tectonic.
NOTE: Source for all slides: FAST 21 conference paper slides, presentation by lead co-author, Satadru Pan
Photo by Kevin Hendersen on Unsplash







