
























































.svg)



































.png)
LinkedIn is the epitome of the modern data-driven enterprise. Its massive global professional social network is powered by its cutting-edge use of analytics, supported by its massive investment in data engineering.
There are many standout examples. Its unified data science and AI platform called Darwin. The dozens of data tools it has built in-house and open-sourced, including Apache Kafka, Flink, and many others.
Most famous is the LinkedIn Knowledge Graph, which depicts the relationships between its 810 million users and 57 million companies to each other. This data is so exclusive and valuable that Microsoft paid $26.2 billion to acquire LinkedIn in 2016.
So it’s wholly appropriate that LinkedIn also operates one of the largest analytics platforms in the world, with approximately 20,000 Hadoop nodes storing one exabyte of data, according to a May 2021 post on the LinkedIn Engineering blog. That is 1,000 petabytes, or one million terabytes.
LinkedIn’s largest data cluster comprises 10,000 nodes storing 500 PB of data including one billion objects (directories, files and blocks), all using the Hadoop Distributed File System (HDFS). That, LinkedIn says, may be the largest Hadoop cluster in the world.
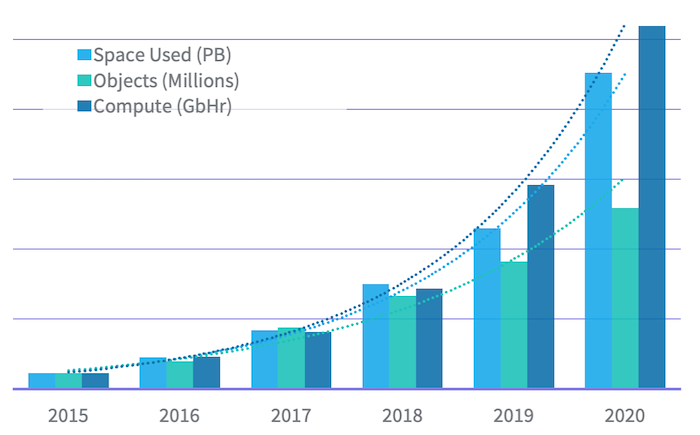
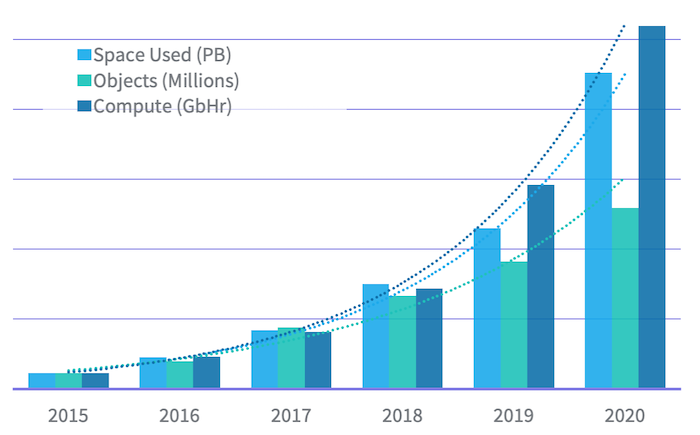
That cluster has grown exponentially (above) in recent years across multiple dimensions:
- Data size: from 20 PB of data in 2015 to 500 PB in 2020
- File objects: from 145 million in 2015 to 1.6 billion in 2020. Despite that growth, its Namespace directory nodes can support remote procedure calls with an average latency under 10 milliseconds.
- Data processing: from 2 million Gigabit-Hours of compute in 2015 to more than 50 million GbHr in 2020. This has accelerated due to Darwin and other machine learning initiatives at LinkedIn, as well as its migration off the proprietary analytics stack that LinkedIn had maintained in parallel to Hadoop for around a decade.
And based on the annual doubling of LinkedIn’s clusters, according to a more recent LinkedIn Engineering blog post, the company could have more than 40,000 nodes by the end of 2022, speculated The Next Platform magazine, along with a commensurate two exabytes of data.
Scaling these massive Hadoop clusters and maintaining desired storage and compute performance has posed many challenges for LinkedIn and its data operations team. They also provide many potential lessons for other companies, whether they are Hadoop users themselves, or — shuddering at Hadoop’s notorious complexity — have chosen a modern low-ops cloud-native alternative instead.
It also shows the importance of strong data observability — whether a home-grown or a turnkey solution — for maintaining high performance and efficiency in a massively scaled-out system.
From Proprietary to Open Source
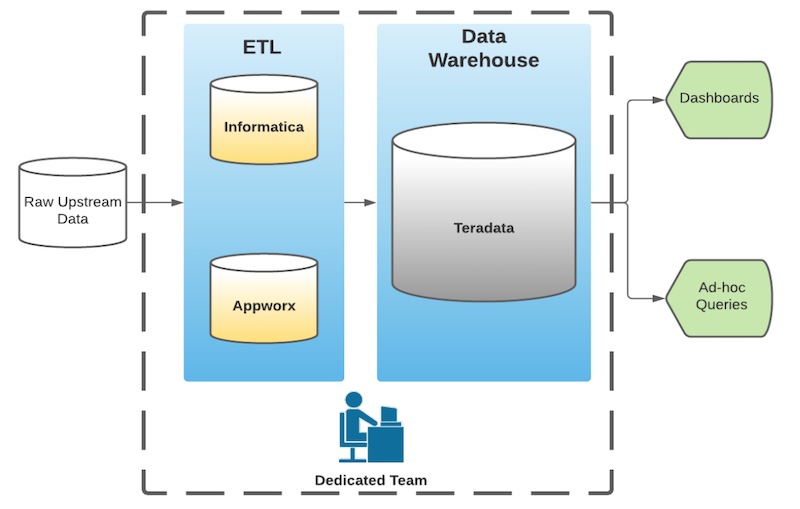
LinkedIn launched in 2003. Like most companies founded in the pre big data era, LinkedIn deployed well-known proprietary business intelligence software of the time: Teradata for its data warehouse and Informatica and Appworx for ETL.
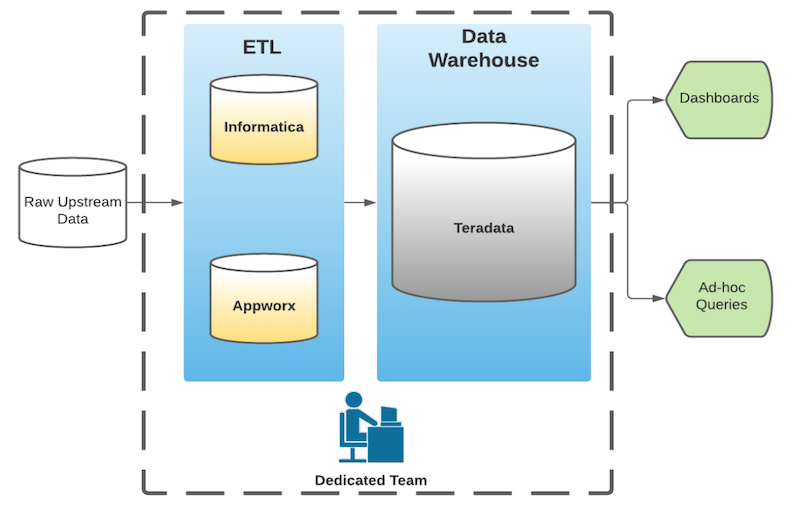
While LinkedIn’s legacy analytics stack (above) “served us well for six years,” it also had two major disadvantages:
- “Lack of freedom to evolve.” LinkedIn had “limited options for innovation,” while “integration with internal and open source systems [was] a challenge.”
- “Difficulty in scaling.” Because of the pricey Informatica and Appwork licenses, data pipeline development was restricted to a small central team at LinkedIn.
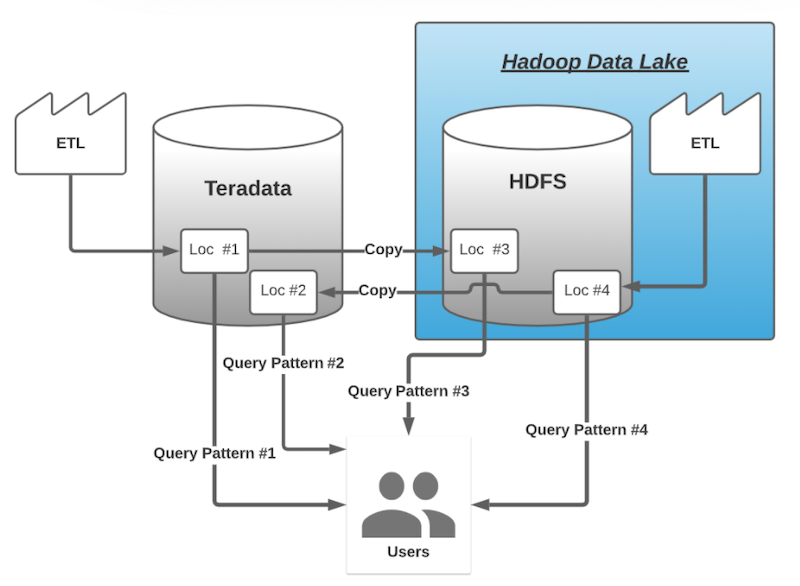
Around 2010, LinkedIn began to build a data lake on Hadoop, while maintaining its proprietary stack. Data was continually replicated between the two stacks (below):

Maintaining dual analytics platforms allowed LinkedIn to dip its toe into a then-new big data platform while maintaining proven stability for its existing mission-critical applications. But it also had several disadvantages:
- Twice the maintenance cost
- Twice the complexity
- Some “very confused” internal users
At some point late last decade, LinkedIn began to plan in earnest for a full migration to Hadoop. That would not be easy. The Teradata/Informatica/Appworx stack included 1,400+ datasets, 900+ data flows, and 2,100+ users. And LinkedIn wanted the migration to be as smooth as possible.
To ensure that, LinkedIn needed information on its dataset lineage and usage to aid in planning and monitoring before and after migration. However, LinkedIn engineers were not satisfied with any of the out-of-the-box solutions available for the Teradata-to-Hadoop migration. And LinkedIn’s DataHub metadata and data discovery tool, which was released open-source in 2019, was still in the planning stages.
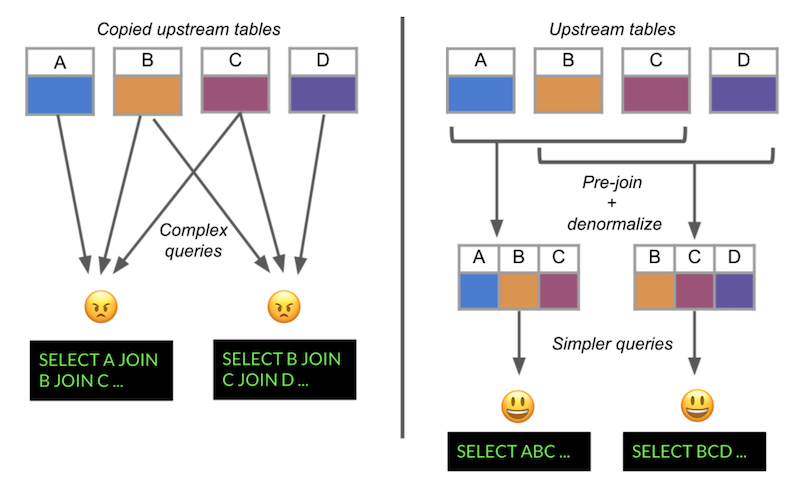
So LinkedIn engineers rolled up their sleeves. The result was a comprehensive data catalog of its Teradata datasets along with all data dependencies. This enabled LinkedIn to shrink the number of datasets from 1,440 to 450, a 70 percent decrease in migration work. LinkedIn also rebuilt its data tables (pre-joining and denormalizing) to make them more analytics-friendly (see below). It also automated the process of migrating users and deprecating datasets.

Despite the scale of the migration, “our tooling and approach allowed for execution that was ahead of schedule with zero negative production impact,” according to LinkedIn. Automating parts of the migration also made the process “less tedious, easier to manage, and only cost a fraction of what we estimated for the manual route.”
The migration also “freed us from the limits imposed by third party proprietary (3PP) platforms and saved millions in licensing, support, and other operating expenses.” It also made it clear that LinkedIn was all in on Hadoop, which jumpstarted LinkedIn’s internal engineering efforts that would bear fruit in many open-source tools.
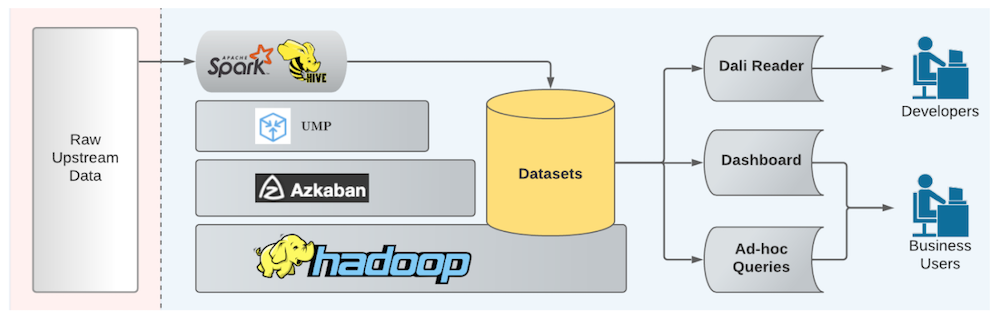
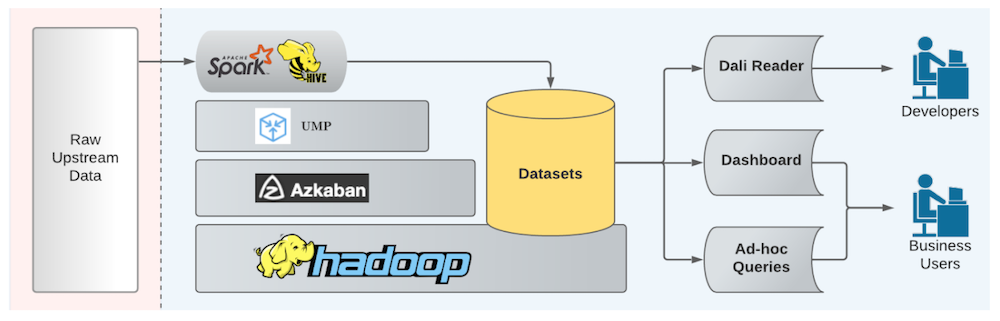
Below is an architectural diagram of the LinkedIn analytics stack, which includes an unified metrics pipeline, a distributed workflow scheduler called Azkaban built by LinkedIn, datasets stored on HDFS, and more.
Like Parent, Like Child
Fewer than a handful of companies have talked publicly about running an analytics platform larger than LinkedIn’s one exabyte-plus Hadoop platform. One of the few is Microsoft, LinkedIn’s parent company since 2016. According to a 2018 blog post by Microsoft Azure CTO Raghu Ramakrishnan, Microsoft processes exabytes of user data every day through multiple Hadoop YARN clusters comprising hundreds of thousands of servers.
Microsoft’s largest YARN cluster is 50,000 nodes, which Ramakrishnan claims is the world’s largest, and is used by 15,000 developers across Microsoft. This is “super-sized analytics,” wrote Ramakrishnan.
Similarly, Facebook has more than a dozen data centers, each holding one exabyte or more of rarely-accessed user photos. Photos in ‘cold storage,’ however, are not the same as an actively used analytic data platform. Facebook publicly talked about its Hive data warehouse for years. That was a comparatively petite 300 PB in size. However, Facebook revealed in 2021 that it had developed a new unified file system called Tectonic for storing data company wide, including “multiple exabytes of data” for its data warehouse.
Other technology behemoths appear to have much smaller analytical data infrastructures than LinkedIn. American bank JPMorgan Chase, which spends $12 billion a year on IT, operates a 450 petabyte internal data mesh. Netflix says its data warehouse stores hundreds of petabytes of data.
Scaling the Storage
Facebook developed Tectonic as a replacement for HDFS and its scalability limitations. While many companies are following Facebook’s lead and moving off HDFS and Hadoop, LinkedIn appears firmly committed, calling Hadoop its “canonical big data platform.”
LinkedIn still uses the classic Hadoop configuration. Data is stored and managed using HDFS, while data is processed using MapReduce and, more recently, Spark. Directory tree and file location information is stored in the memory of a dedicated server called a NameNode.
Originally, each cluster had a single NameNode. However, as LinkedIn’s clusters grew in size, HDFS file performance slowed, while NameNode became more vulnerable as a potential Single Point of Failure (SPOF).
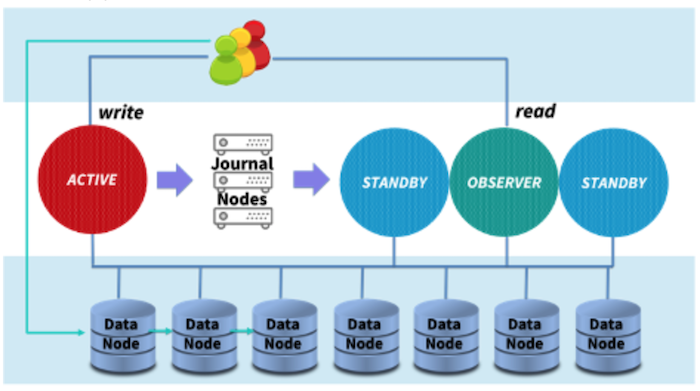
Things reached a tipping point in 2016. The first thing LinkedIn addressed was high availability. LinkedIn changed so that every cluster has multiple replicated NameNodes. If the Active NameNode fails, one of the Standby ones that has been ingesting new data and updating its namespace info in the background can quickly take over. LinkedIn uses Quorum Journal Manager (QJM) to keep the Active and Standby NameNodes up to date and switch them in case one fails. Upgrades of the NameNodes can be done in a rolling fashion to make sure there is no downtime.
LinkedIn also began addressing storage performance issues. By that point, LinkedIn’s largest NameNode server had to keep track of the file and directory information of 1.1 billion namespace objects. That translated into a 380 GB Java heap, all of which was maintained in RAM for fast access. LinkedIn engineers did extensive tinkering in how memory was purged, and how NameNode requests were prioritized. This helped accelerate the handling of read-write requests, while still sufficiently protecting the namespace information from potential corruption.
Solving the Small Files Problem
Another cause for sluggish performance was the preponderance of small files in LinkedIn’s clusters. It is well-known that small files are much slower to read and write than large files, for two main reasons. First is the performance penalty of processing multiple small files in different locations in parallel rather than a single large contiguous file, aka the difference between random and sequential I/O. And in a massive exabyte-sized cluster, what constitutes small can be rather large. In LinkedIn’s cluster, anything smaller than the 512 MB disk block size was considered small.
The second reason is that every file has a minimum amount of file and directory metadata associated with it. Therefore, ten small files equivalent in size to one large one would create approximately ten times the namespace information. In a massive cluster, processing the namespace information can quickly become the bottleneck for the NameNode.
LinkedIn engineers discovered that a huge number of the small files were frequently-accessed configuration and log files used by Hadoop-owned services and stored in the system folder. To rebalance the load, they copied the system folder to a separate satellite cluster. This freed up the primary cluster and its NameNode server to speedily handle user requests again.

LinkedIn also reprogrammed its standby backup NameNode to become an “observer” NameNode (above), meaning that it could help serve file read requests even while it served as a potential failover NameNode in case the primary Active one crashed.
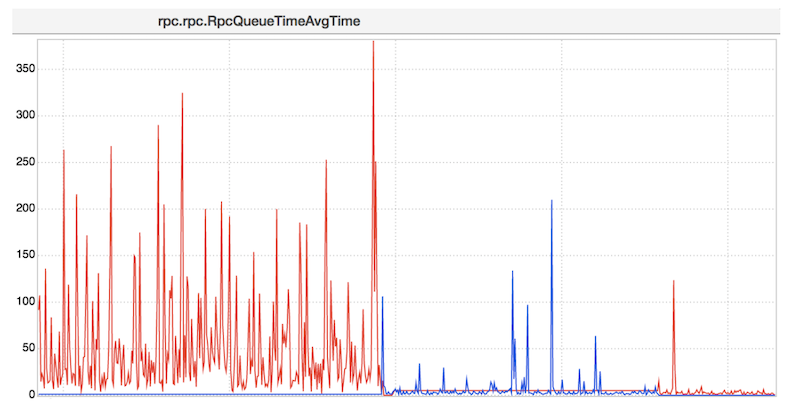
These and other optimizations to HDFS have all boosted NameNode responsiveness, which is crucial to boosting the overall performance of the HDFS file system. Post-optimization, LinkedIn’s NameNodes can perform 150,000 operations per second, peaking at 250,000 ops/second, with an average latency of 1-2 milliseconds.

Optimizing Compute Performance
Besides optimizing storage performance and stability, LinkedIn took many steps to boost the compute performance of its Hadoop cluster. YARN, which stands for Yet Another Resource Negotiator, is the software that manages and assigns compute jobs in Hadoop. A much lighter weight application than NameNode, YARN’s performance hadn’t started suffering until 2019, when LinkedIn’s largest clusters started approaching 10,000 nodes in size.
LinkedIn has traditionally had two Hadoop clusters per data center: one for main traffic and another for data obfuscation. While the primary cluster was often maxed out, the secondary usually had idle compute cycles. To improve resource utilization, LinkedIn merged the two clusters into one cluster with separate primary and secondary partitions. The idle compute nodes from the secondary partition were moved into the primary one.
This worked well for several months. Soon, users began to complain that their data jobs would take hours to be scheduled, even when the cluster was free. The first round of debugging yielded small speed improvements, but the delay remained large for many users.
More investigation by LinkedIn engineers revealed that the primary partition remained overloaded with elaborate AI experiments and data analyses running in Spark, while the secondary partition’s workloads were mostly “fast churning MapReduce jobs.” Rebalancing the workloads again provided only temporary relief. After another round of investigation, LinkedIn figured out that killing the First In, First Out (FIFO) scheduler in YARN enabled it to avoid paralyzing bottlenecks. This led to a 9x performance increase.
Building Its Own
As a cutting-edge Silicon Valley company, LinkedIn had the resources to take another step to extend the scalability of the single-threaded YARN application: build its own tools for performance monitoring, forecasting, and job scheduling. They included:
- Azkaban, the aforementioned workflow job scheduling tool that LinkedIn made open source
- Robin, a load balancing tool that works in the background with Azkaban to send YARN applications to free Hadoop clusters
- DynoYARN, a performance forecasting tool that LinkedIn also open sourced. DynoYARN can spin up simulated YARN clusters and workloads and predict their performance. LinkedIn uses DynoYARN to test before any major deployments or feature upgrades.
Future in the Cloud
For many reasons, including its relatively recent migration of all its analytics applications to Hadoop, LinkedIn appears firmly committed to Hadoop.
Still, the company is such a trailblazer it cannot help but move forward on technology. In 2019, LinkedIn announced that it had begun a multi-year migration of its on-premises Hadoop clusters to the Azure public cloud owned by parent Microsoft. Azure strongly supports Hadoop, and Microsoft has been heavily wooing on-premises Hadoop users to migrate their data lakes to their cloud, promising cost-efficiency, instant scalability, “a unified experience, and unmatched security.”
LinkedIn has already moved several data-related applications to Azure, which has helped “accelerate video post-delivery, improve machine translation in the Feed and keep inappropriate content off our site.”
LinkedIn acknowledges the Azure migration brings both challenges and opportunities. Challenges include “handling noisy neighbors, disk utilization aware scheduling to decrease costs, and job caching,” while opportunities include “spot instances, auto scaling” and more.
If you’d like to keep abreast of LinkedIn’s many data engineering innovations, follow their LinkedIn Engineering blog.
If your organization lacks LinkedIn’s massive data engineering team or the resources to build your own data observability tools, then check out the Acceldata data observability platform, which provides essential multidimensional data observability for modern data infrastructures at a fraction of the deployment time and cost of building your own like LinkedIn. Request a demo here.
Photo by Alina Grubnyak on Unsplash








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}