
























































.svg)



































.png)
Data engineers face the continuously growing challenge of meeting their organization's increasing demand for new data workflows. They are tasked with capturing new forms of data with the hope of harnessing them for new analytics while maintaining the highest levels of data quality.
It’s a question that every data team faces: How can we scale data reliability efforts to meet these challenges?
At a high level, data reliability requires an approach that drives how data operates throughout its lifecycle. But as in any system, the approach has to be buttressed by specific guidelines and prescription actions. This is why data reliability also requires rules.
Scaling Data Reliability with Rules
An essential step in ensuring data reliability is the implementation of numerous rules to govern and manage the assessment and validation of specific conditions associated with data sources. Data rules provide the framework for how your data is intended to operate. In legacy tools, these rules typically operate in a static way; they only apply for a specific purpose and in a specific context.
But data environments are in a state of constant change, so they need rules that can expand data profiling analysis, enhance data quality testing, and provide greater insight into data integration needs. When applied in the right way, data rules can serve various purposes, such as evaluating and analyzing conditions discovered during data profiling, conducting data quality assessments, providing additional information for data integration, or establishing a framework for continuous data quality validation and measurement.
Data engineers are constantly dealing with the increase in data sources and the orchestration of them as they interact with other sources. The Acceldata Data Observability platform provides the ability to apply bulk policies to the guidelines and rules for these data sources that allow teams to achieve their goal of adding the requisite data to their systems, while ensuring data reliability is achieved, AND that it isn’t compromised as the environment evolves. Using rules and rule sets to achieve data reliability at scale is one of the key differentiators of the Acceldata Data Observability platform. Let’s look more closely at how Acceldata users can do this.
Applying Rules in a Data Environment
As more data sources are incorporated into the Acceldata Data Observability platform, the number of assets associated with each source increases significantly. Manually adding required rules to every asset to ensure data reliability can be a tedious and time-consuming task. For instance, when adding a data source with 100 assets, it becomes cumbersome to add similar policies to each asset individually.
Fortunately, the Acceldata platform offers a solution to this problem through the Bulk Policies feature. By creating a set of rules to be added to the data quality policy and grouping them together, you can apply the rule group to a data source. ADOC then automatically generates a Data Quality policy and applies all the rules in the group to all assets in the data source that meet a tag-based condition. This feature streamlines the process of ensuring data reliability and eliminates the need for manual policy creation on each asset.
The actual process of applying rules to all qualifying assets requires a few steps - let’s look at what they look like inside the Acceldata platform.
How to Create a Rule
To establish quality rules for a data asset, it's crucial to have the right context, which can be challenging, especially when dealing with a large amount of data columns. However, with Acceldata, you can effortlessly obtain an automated profile of your data asset that includes an interactive statistical summary, simplifying the process of creating quality rules. (see below)
First, you and your team will know the required rules and where they apply. Create the rules to be included in the Data Quality policy. Additionally, ensure that the same tag is added to the rule and all qualifying assets.

As you can see, Acceldata offers intuitive charts and graphs that offer valuable context to help you comprehend your data and its sources, activity, and status.
As we drill in further, we see that the Rules page displays a list of all the rules created in a table. The columns of the table are described here:

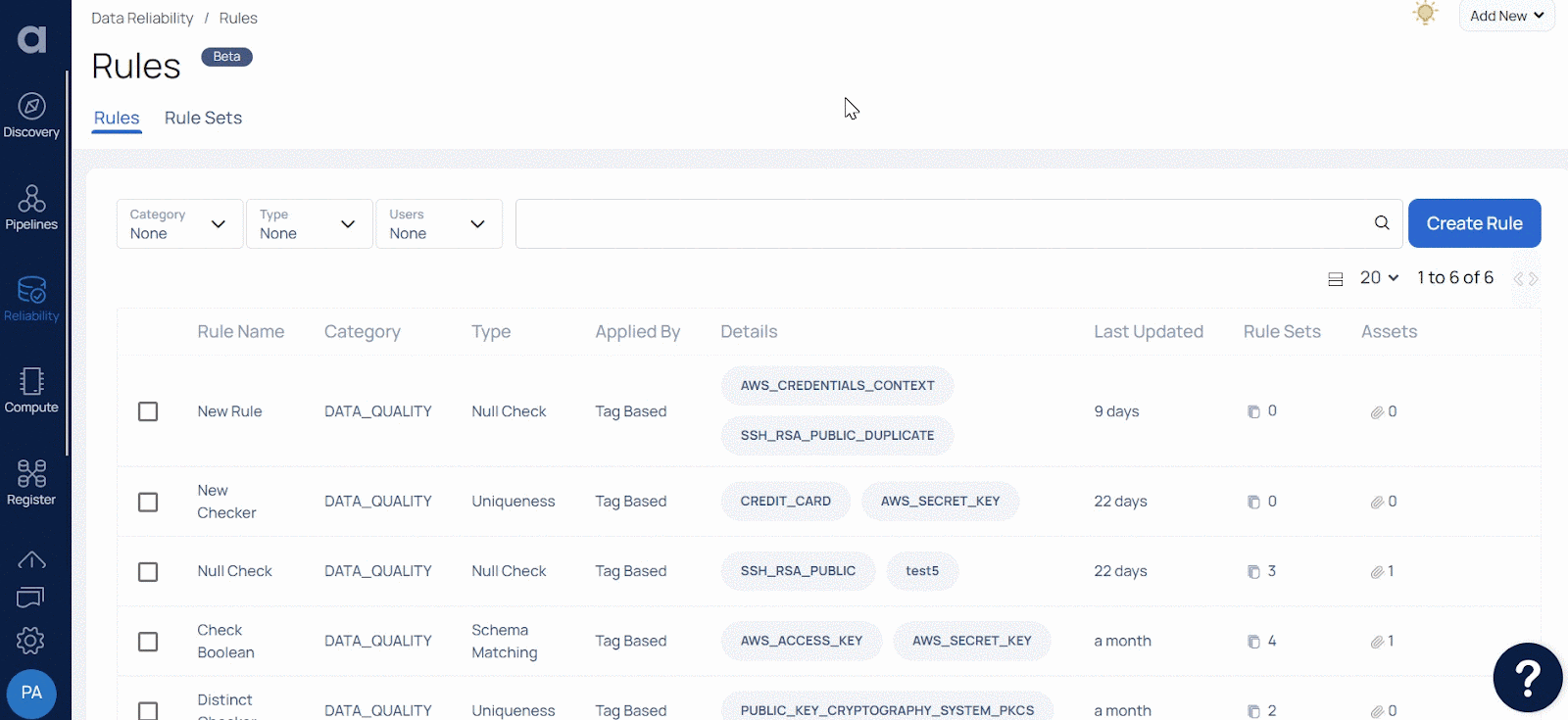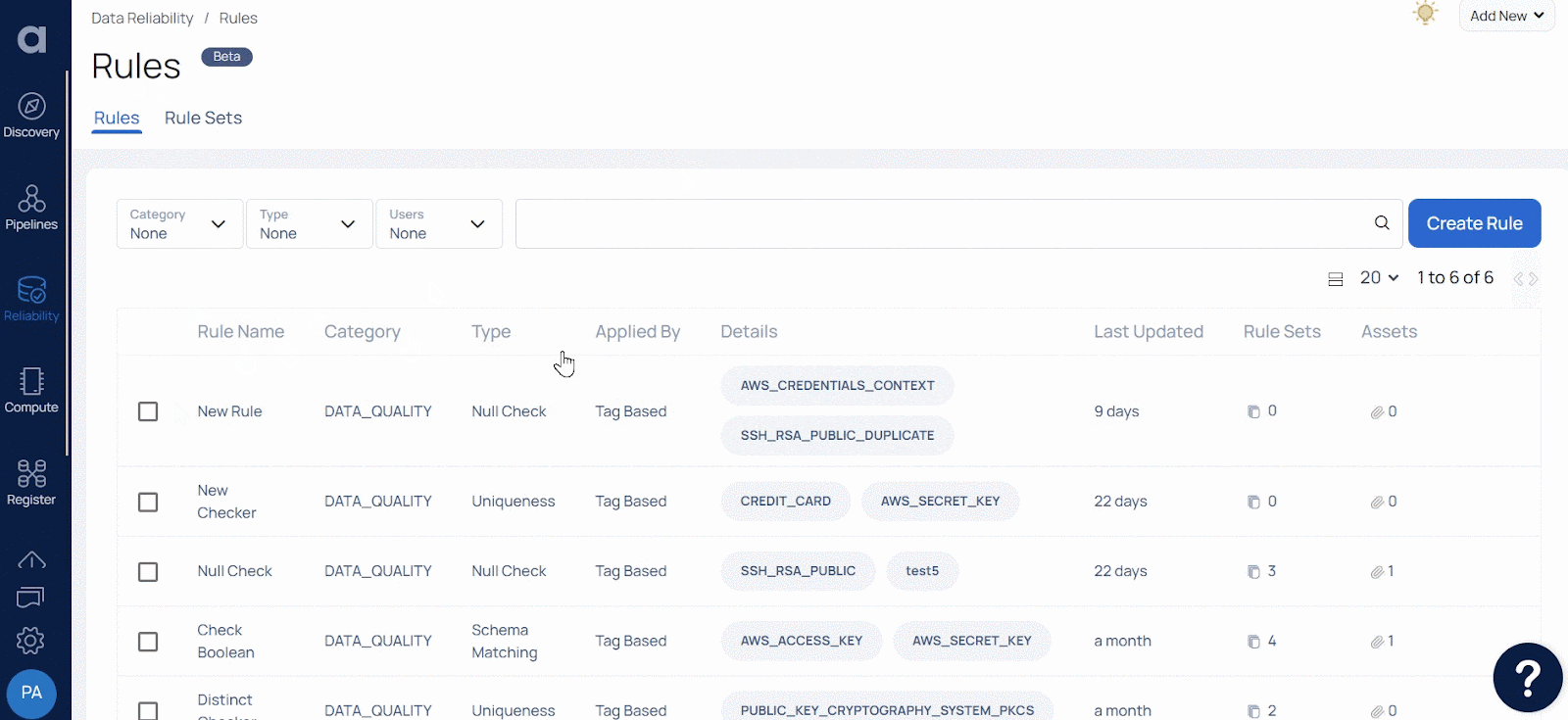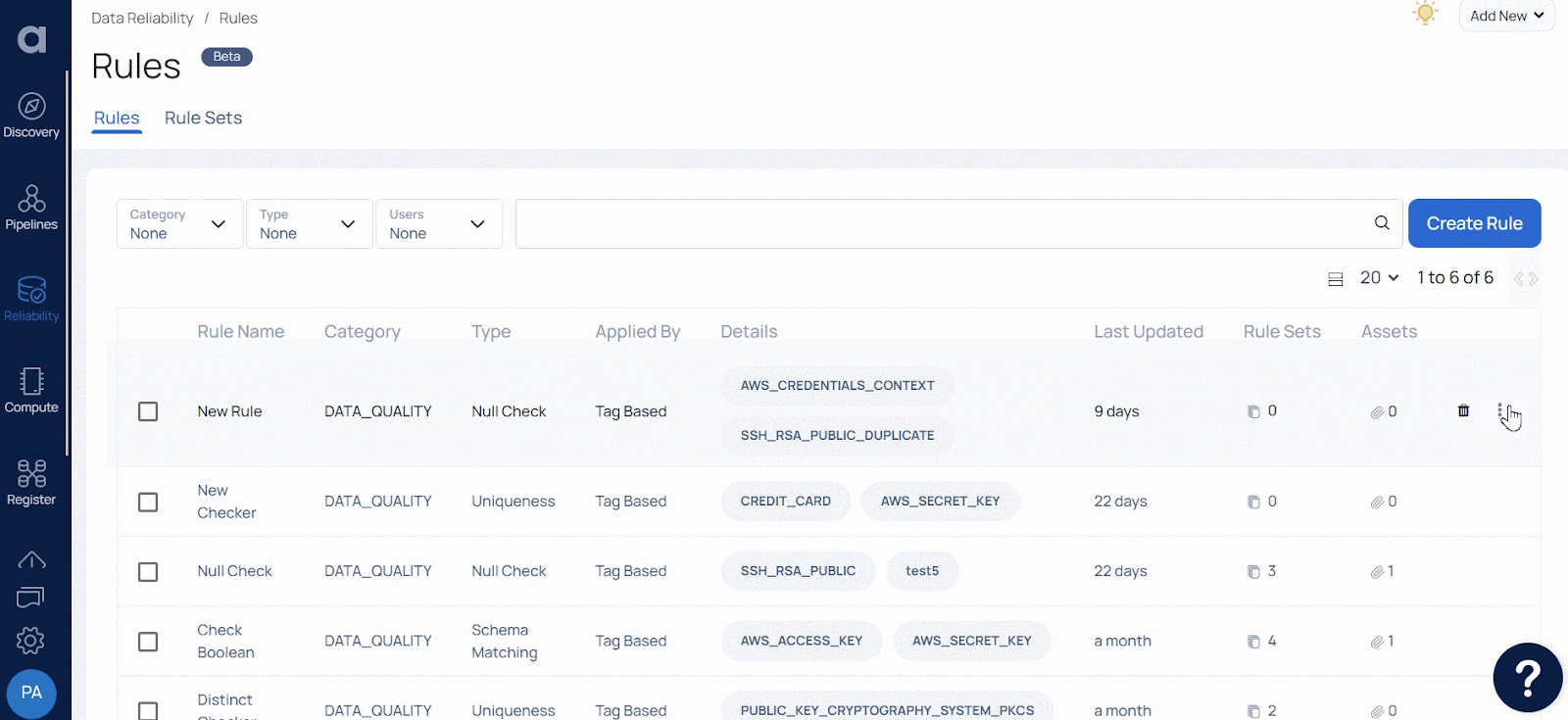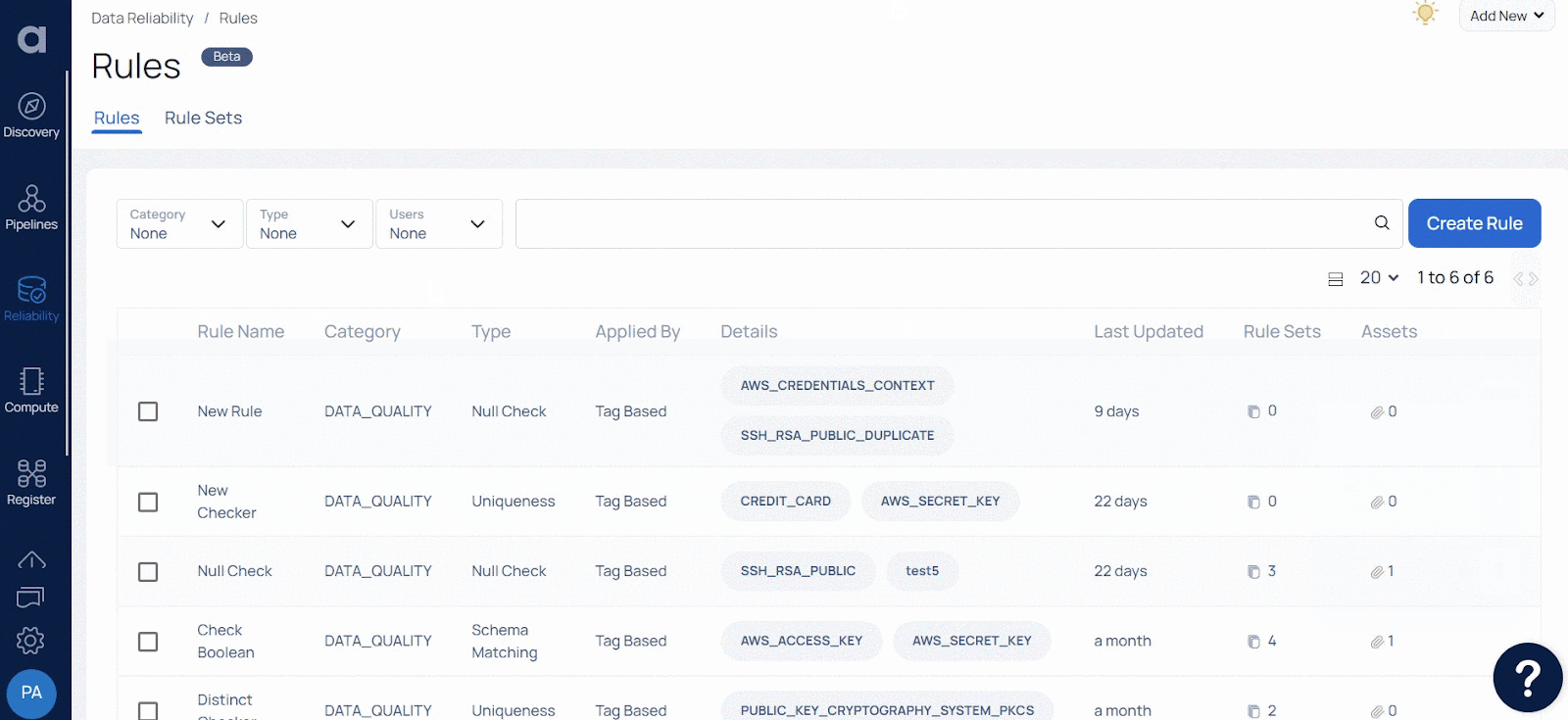
How to Create Rule Definitions
As we’ll see next, using Acceldata to profile your data sets a benchmark for effectively developing data quality policies and regulations.
Acceldata allows you to customize how your rules are manifested. Based on the rule type you select, you then specify values for some of the additional fields which are specific to the rule and how it governs the data. Rule definitions are important to understand because they establish consistency. These definitions include things like [italic]schema match, null values, pattern match, enumerations, and others. To learn more about Data Quality policy rules, see our documentation on Rule Definitions.
The ability to add rule definitions, descriptions, and related tags are included in the rule dashboard:

How to Create Rule Sets
A collection of rules is called a rule set, and you need to add them to apply them to a data source. You can't implement a rule directly on a data source. To access the rule set page, simply click on the "Rule Sets" tab located on the "Rules" page. On the Rule Sets page, a table displays the list of all created rule sets. This table includes the following columns:

Once you create rules and add them to a rule set, you must apply the rule set to a data source, database, schema, or a Big Query dataset. When you apply the rule set, all the assets in the data source/database/schema/big query data set are scanned to check if they have the same tag as present in the rules. A data quality policy is created on all the assets which match the tags of the rules present in the rule set and the rules are added to the data quality policy.

Traditional data reliability methods aren’t equipped to scale. Rather, their focus is on specific instance rules that apply in a static state. The problem with that is that data environments are constantly changing, and the application of rules in Acceldata adapt as the data sources and interactions change. You can think of the Acceldata platform as an orchestrator of rules rather than as just a facilitator of prescribed guidelines.
Get a demo of the Acceldata Data Observability Platform and learn how you can optimize your data spend, improve operational intelligence, and ensure data reliability.
Photo by Tom van Hoogstraten on Unsplash







