
























































.svg)




































We are witnessing a sudden and massive burst of excitement, along with much confusion, over the rapidly proliferating use of generative AI based tools like ChatGPT, Bard, Llama, Anthropic, and others. For enterprises, it can seem like an almost existential threat, as in, use AI/ML or else be left behind to be forgotten. It is not quite that ominous yet, but if you’ve had any exposure to these tools, you get the point.
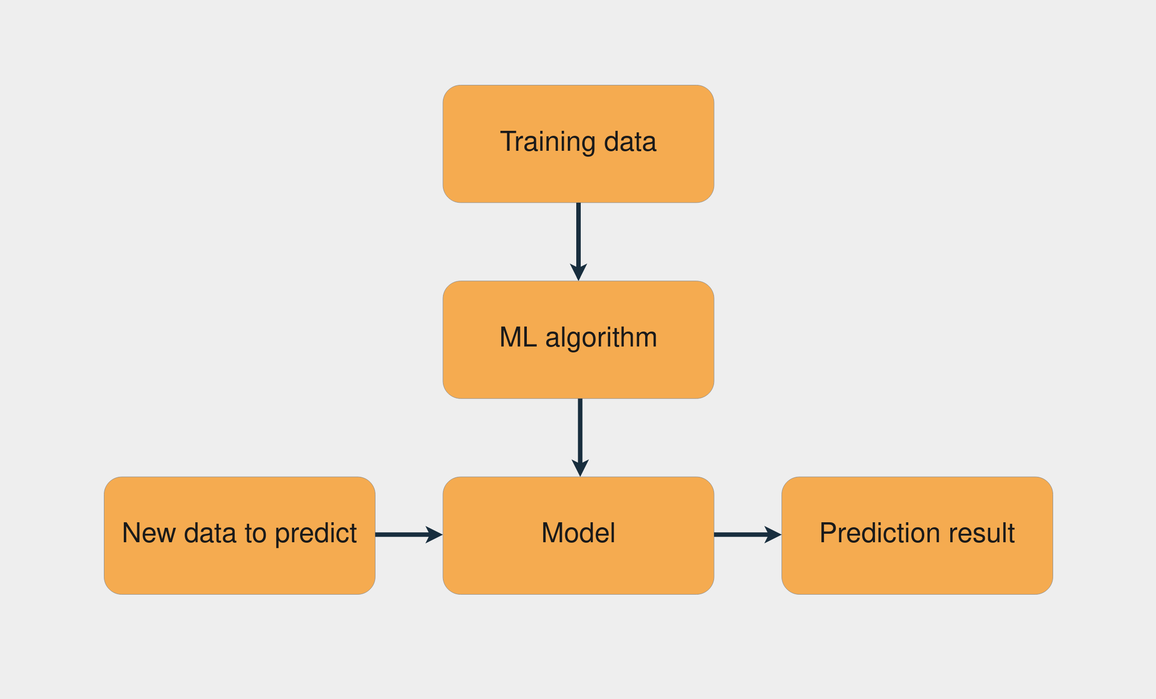
In order to truly understand the potential impact of these large language model (LLM)-based tools, let's look at it through the perspective of risk, as the biggest risk to their efficacy and utility is bad, unreliable, inaccurate data.
An AI/ML model starts simply as an algorithm (program) to represent the hypothesis/assumptions of a behavior. The behavior is “validated” using a small set of data first. Then, the model is “trained” on a reasonably large set of data. This codifies the behavior of the model in a variety of situations and circumstances, i.e. data. Once the model is trained, you now deploy it, pass a new set of data and let the model “predict” the outcome based on its learned behavior and the input data. This, of course, is a highly simplified description as there are numerous variations and nuances to consider in practice.
As you can see from the simple process diagram above, data plays a crucial role at every stage of development and training of an AI/ML model. Data is the raw material for all AI/ML goodness. The data “ingredients” fed into the model dictate both the content of the model’s output, as well as the efficacy of it. Therefore, as goes the data, so goes the model! Another analogy is one that describes the work done by artists and artisans. They make beautiful things out of raw material. If the materials they use and depend on are not of good quality, how do you expect the outcomes to be of any good value?
Let’s consider the value of data and why we need to ensure it is reliable and usable. Imagine if there are errors in the medical records, or in the training sets used to create predictive models. These models are simply operating off the data available to them, and if that data is bad, the resulting consequences could lead to an improper diagnosis or treatment plans that put a patient at risk. Bad data, therefore, could potentially be fatal, a situation that sheds light on a key risk factor for AI implementations: the quality of your data. Of course, as goes the data, so goes the model!
Autonomous driving systems go through the same sort of model training. Like babies, they learn by mimicking other people’s behavior, responses and mistakes. A model can never be fool-proof as in always predicting the correct outcome, but through enough data and continuous training/learning (also called reinforced learning), it can have a high degree of reliability. Of course, as goes the data, so goes the model!

Challenges: Data for AI
Here’s a rundown of many data factors that can cause models to derail:
- Model Drift or Concept Drift refers to the evolution of data that invalidates the data model. It happens when the statistical properties of the target attributes, which the model is trying to predict, change over time in unforeseen ways. Imagine that an ML model was trained to detect spam emails based on the content of the email. If the types of spam emails that people receive change significantly, the model may no longer be able to accurately detect spam.
- Data Drift or Inconsistent Data occurs when the distribution of the input data changes over time and can drastically change the accuracy of algorithms. For example, consider a machine learning model that was trained to predict the likelihood of a customer purchasing a product based on their age and income. If the distribution of ages and incomes of the customers changes significantly over time, the model may no longer be able to predict the likelihood of a purchase accurately.
- Feature Drift is a shift in the model’s input data distribution. As an example, incomes of all applicants increase by 5%, but the economic fundamentals are the same.
- Prediction Drift is a shift in the model’s predictions. Monitoring for prediction drift allows you to measure model quality. For example, a larger proportion of credit-worthy applications are typically approved when a product was launched in a more affluent area. Your model is still valid, but your business may not be prepared for this scenario
Ensuring Reliable Data for AI
So, what are you supposed to do?
Well, not all is lost. Data teams who recognize the critical value of reliable data apply data observability, which offers the monitoring of data, data pipelines, and data platforms, and helps prevent havoc caused by data gone wrong. It provides orchestrated visibility across data platforms, applications, and all data sources to monitor and adjust data and data processes continuously. Data reliability is not a one-and-done scenario, however. Data by nature constantly goes through anomalies, drifts, and other changes. Another valuable approach is to shift-left the data reliability checks so data can be monitored and alerted early, before downstream processes start failing or bad business decisions are made.
Here are a few high level issues you need to address with your data as you prepare to employ AI in your data strategy.
- Get your data house in order first. This was the theme at the two main data conferences this year.
- Be outcome-driven. Destination becomes more important than the journey.
- Emphasize that your enterprise AI strategy, like other IT-related strategies, should focus on people, process and tech.
- AI as an assistive/augmented intelligence is for and about people. Invest in continuous AI education.
Photo by Vlado Paunovic on Unsplash







