
























































.svg)




































As data analytics have become increasingly critical to an organization’s operations, more data than ever is being captured and fed into analytics data stores, with the hope that it will help enterprises make decisions with greater accuracy. Data reliability is therefore essential to enable enterprises to make the right decisions based on the right information.
This data comes from a variety of sources. Internally, they come from applications and repositories, while external sources include service providers and independent data producers. For companies that produce data products, it’s typical that they get a significant percentage of their data from external sources. And since the end product is the data itself, reliably bringing together the data with high degrees of quality is critical.
What Does Shift Left Mean?
The starting point for doing that is to shift left the entire approach to data reliability to ensure that data entering your environment is of the highest quality and can be trusted. Shifting left is essential, but it’s not something that can simply be turned on. Data Observability plays a key role in shaping data reliability, and only with the right platform can you ensure you’re getting only good, healthy data into your system.
High-quality data can help an organization achieve competitive advantages and continuously deliver innovative, market-leading products. Poor quality data will deliver bad outcomes and create bad products, and that can break the business.
The data pipelines that feed and transform data for consumption are increasingly complex. The pipelines can break at any point due to data errors, poor logic, or the necessary resources not being available to process the data. The challenge for every data team is to get their data reliability established as early in the data journey as possible and thus, create data pipelines that are optimized to perform and scale to meet an enterprise's business and technical needs.
In the context of data observability, "shift left" refers to a proactive approach of incorporating observability practices early in the data lifecycle. It is a concept borrowed from software development methodologies, where it emphasizes addressing potential issues and ensuring quality at the earliest stages of development.
When applied to data observability, shifting left means integrating observability practices and tools into the data pipeline and data infrastructure from the beginning, rather than treating it as an afterthought or applying it only in the later stages. The goal is to catch and address data quality, integrity, and performance issues as early as possible, reducing the chances of problems propagating downstream.
The data within the data pipelines that manage data supply chains typically operate in one of three sections:
- The data landing zone, where source data is fed
- The transformation zone, where data is transformed into its final format
- The consumption zone, where data is in its final format and is accessed by users
In the past, most organizations would only apply data quality tests in the final consumption zone due to resource and testing limitations. The role of modern data reliability is to check data in any of these three zones as well as to monitor the data pipelines that are moving and transforming the data.
Cost Implications of Poor Data
In software development, as well as other processes, there is the “1 x 10 x 100 Rule” which applies to the cost of fixing problems at different stages of the process. It says that for every $1 it costs to detect and fix a problem in development, it costs $10 to fix the problem when that problem is detected in the QA/staging phase, and $100 to detect and fix it once the software is in production. In essence, it’s far more cost-effective to fix it as early as possible.
The same rule can be applied to data pipelines and supply chains. For every $1 it costs to detect and fix a problem in the landing zone, it costs $10 to detect and fix a problem in the transformation zone, and $100 to detect and fix it in the consumption zone.
To effectively manage data and data pipelines, data incidents need to be detected as early as possible in the supply chain. This helps data teams optimize resources, control costs, and produce the best possible data product.
Shift-left Data Reliability
We mentioned earlier how data supply chains have gotten increasingly complex. This complexity is manifested through things like:
- The increasing number of sources that are being fed.
- The sophistication of the logic used to transform the data.
- The number of resources required to process the data.
Consider the diagram below where data pipelines flow data from left to right from sources into the data landing zone, transformation zone, and consumption zone. Where data was once only checked in the consumption zone, today’s best practices call for data teams to shift left their data reliability checks into the data landing zone.

The result of shift-left data reliability is earlier detection and fast correction of data incidents. It also keeps bad data from spreading further downstream where it might be consumed by users and could result in poor and misinformed decision-making.
The 1 x 10 x 100 rule applies here. Earlier detection means data incidents are corrected quickly and efficiently at the lowest possible cost (the $1). If data issues were to spread downstream they would impact more data assets and become far more costly to correct (the $10 or $100).
What Does It Take to Shift Left?
The ability for your data reliability solution to shift left requires a unique set of capabilities to be effective. This includes the ability to:
- Perform data reliability checks before data enters the data warehouse and data lakehouse: The ability to execute data reliability tests on data earlier in the data pipelines keeps bad data out of the transformation and consumption zones.
- Support for data-in-motion platforms: Supporting data platforms such as Kafka and monitoring data pipelines in Spark jobs or Airflow orchestrations allows data pipelines to be monitored and metered.
- Support for files: Files are often delivering new data for data pipelines. Performing checks on the various file types and capturing file events to know when to perform incremental checks is important.
- Circuit-breakers: These are APIs that integrate data reliability test results into your data pipelines to allow the pipelines to make decisions to halt data flow when bad data is detected. This prevents it from infecting other data downstream.
- Data isolation: When bad data rows are identified they should be prevented from continued processing, then they need to be isolated, and ultimately, need to have the ability to have further checks run to dig deeper into the problem.
- Data reconciliation: With the same data often in multiple places, the ability to perform data reconciliation allows data to remain in sync in various locations.
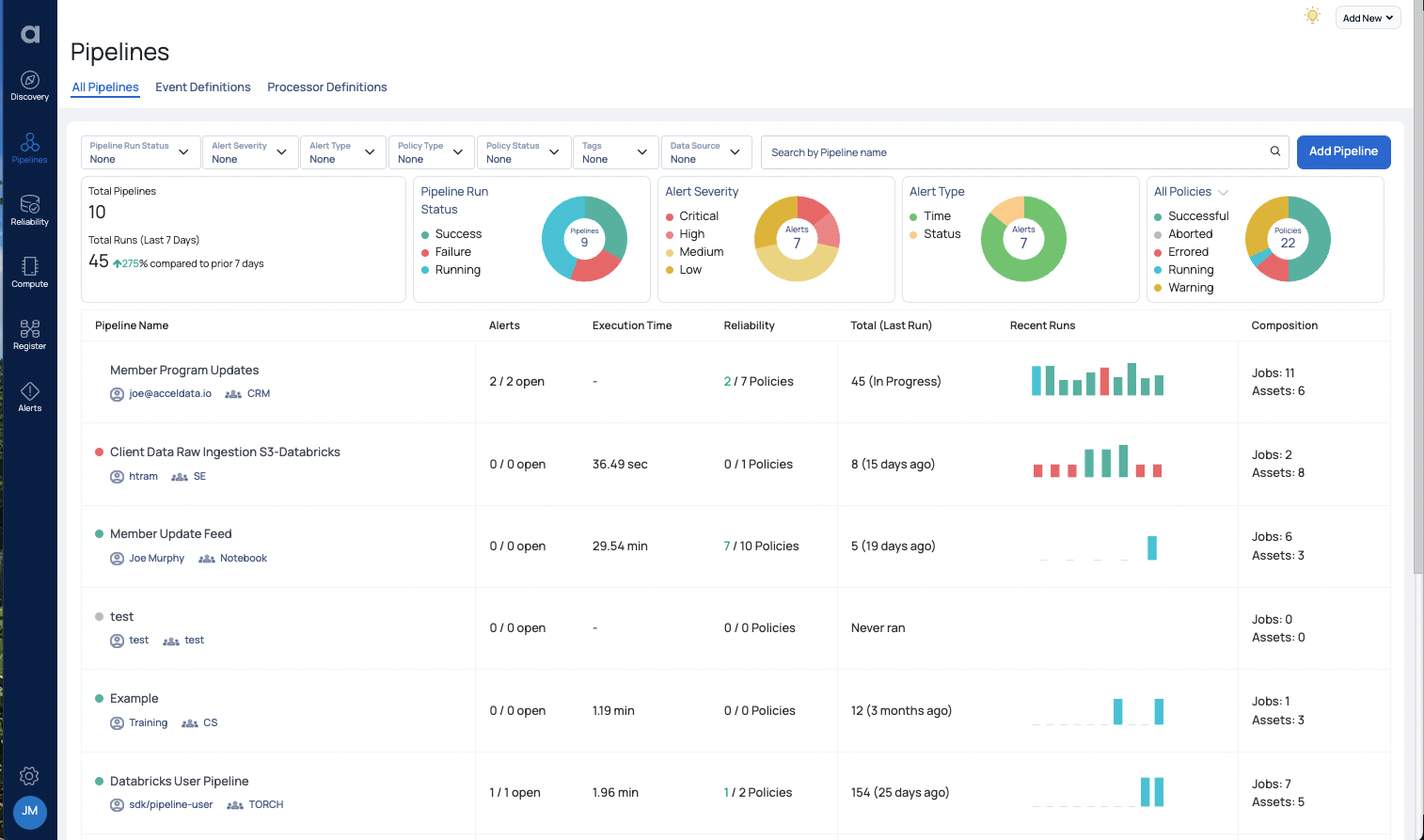
Continuous Monitoring
There needs to be continuous monitoring of data pipelines to detect issues early and keep the data healthy and flowing properly. A consolidated incident management and troubleshooting operation control center allows data teams to get continuous visibility into data health and enables them to respond rapidly to incidents.
To support continuous monitoring, data reliability dashboards and control centers should be able to:
- Offer instantaneous, 360o insights into data health.
- Provide alerts and information on incidents when they occur.
- Integrate with popular IT notification channels such as Slack.
- Allow data teams to drill down into data about the incident to identify the root cause.

Identifying and Preventing Issues
To quickly identify the root cause of data incidents and remedy them, data teams need as much information as possible about the incident and what was happening at the time it occurred. Acceldata provides correlated, multi-layer data on data assets, data pipelines, data infrastructure, and the incidents at the time they happened. Armed with this information, data teams can:
- Perform root cause analysis of any incident and make adjustments to data assets, data pipelines, and data infrastructure accordingly.
- Automatically re-run data pipelines when incidents occur, which allows them to quickly recover.
- Eliminate bad or erroneous data rows to keep data flowing without the low quality rows.
- Compare execution, timeliness, and performance at different points in time to see what’s changing.
- Perform time-series analysis to determine if data assets, pipelines, or infrastructure is fluctuating or deteriorating.
Preparing to Shift Left Your Data Reliability
Shifting left your data reliability allows your data teams to detect and resolve issues earlier in a data pipeline and prevents poor-quality data from flowing further downstream. Shifting-left helps:
- Free data teams from firefighting data issues, which allows them to spend more time innovating on new projects.
- Lower the cost of fixing data issues, per the 1 x 10 x 100 rule, which helps reduce overall data engineering costs.
- Ensures low-quality data does not hit the consumption zone. That gives business teams greater trust in the data they use.
- Keep data pipelines flowing properly so data remains timely and fresh, facilitating agile business processes.
Get a demo of the Acceldata Data Observability platform and learn how you can shift left data reliability for smooth and effective data reliability processes.
Photo by Yeshi Kangrang on Unsplash









