
























































.svg)




































Since it was launched in 2013, Apache Spark has become the leading tool for data engineers to work with large datasets.
As enterprises are increasingly challenged with the management and governance of massive troves of data that live in, and transact with, multiple sources, Spark has become among the most important tools in a data engineer's arsenal.
The Acceldata platform has a Spark integration and provides a convenient dashboard that enables data engineers to observe and manage streaming Spark data. This is a major advantage for data engineers, but it’s also important for them to understand typical use cases and how Spark operates in practice.
Apache Spark - Origins and Purpose
At a high level, Spark is a unified analytics engine for large-scale data processing. Data engineers incorporate Spark into their applications to rapidly query, analyze, and transform data at scale.
To understand the context, consider that the goal of the original Spark project was to keep the benefits of Hadoop MapReduce’s scalable, distributed, fault-tolerant processing framework, while making it more efficient and easier to use.
It began its life in 2009 as a project within the AMPLab at the University of California, Berkeley. Spark was donated to the Apache Software Foundation in 2013 and became a top-level project in 2014. The Apache Spark community is large, active, international, and includes a diverse set of commercial providers including Databricks, IBM, and all of the main Hadoop vendors who deliver comprehensive support for Spark-based solutions.
How, and Where, Spark is Applied - Use Cases
Data engineers continuously face increasingly larger datasets, more diverse sources of data, and the continuous feed of real time analytics. Their skill sets are aligned with these tasks, but the massive increase in scale makes it difficult to manage and deliver effective outcomes with the data they manage.
Apache Spark can help with many of these tasks because it is especially suited for:
- Stream processing: From log files to IoT data, applications are increasingly having to deal with a “stream” of data (data that is generated from multiple, and often diverse, sources). While it can be stored, in many cases it is imperative to process and act upon the data in real time in order to get the most value as the data is generated.
- Machine learning: With the growing scale of data, training machine learning models and gaining accurate insights from them becomes more and more feasible. Spark’s ability to store data in memory and rapidly run repeated queries makes it a good choice for training machine learning algorithms.
- Interactive analytics: As businesses become more reliant on being able to act upon data as it arrives at a source (examples might include instances where the end-user, or data consumer, needs to change strategies based on stock prices or production line bottlenecks), data engineers need to be able to interactively query data. Spark allows them to quickly view, modify, or drill down on their questions to respond and adapt quickly.
- Data cleansing: Cleaning data is usually the most time intensive and laborious task for data engineers. Extract, transform, and load (ETL) processes are often used to pull data from different systems, clean and standardize it, and then load it into a separate system for analysis. Spark can drastically reduce the cost and time of the ETL process.
How Does Apache Spark Function?
Spark is capable of scaling data processing from a few megabytes of data on a laptop to handling several petabytes of data, distributed across a cluster of thousands of cooperating physical or virtual servers.
It consists of a core data processing engine and additional libraries for SQL, machine learning, graph computation, and stream processing, which can be used together in an application. Data engineers can leverage a variety of languages including Java, Python, Scala, and R to work with their data and data can be accessed from multiple sources including HDFS, Cassandra, HBase, Hive, Kafka, S3, and MongoDB.
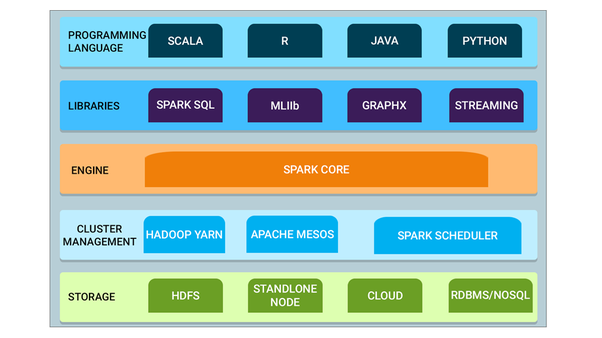
Spark Core is responsible for memory management and fault recovery, scheduling, distributing and monitoring jobs on a cluster and interacting with storage systems. The core engine is optimized to run in memory. This helps it process data faster than alternative approaches like Hadoop’s MapReduce, which usually writes data to and from disk between each stage of processing.
By reducing the number of read-write cycles and storing intermediate data in memory, Spark can run applications up to 100x faster in memory and 10x faster on disk than Hadoop MapReduce.
On top of the core engine, there are additional libraries for SQL, machine learning, graph computation, and stream processing. These include the following:
- Spark SQL allows the use of SQL queries to query non-relational distributed databases.
- MLlib stands for Machine Learning Library. Spark MLlib is used to perform machine learning in Apache Spark.
- GraphX is the Spark API for graphs and graph-parallel computation.
- Spark Streaming is the component of Spark which is used to process real-time streaming data.
While not actually a part of Spark itself, Spark is built to run on top of a cluster manager. A cluster manager is used to acquire cluster resources for executing jobs. Spark core can run on many cluster managers including Hadoop YARN, Apache Mesos, Amazon EC2, and Spark’s built-in cluster manager.
Apache Spark is a versatile tool for data engineers to deal with their data processing needs across any type of environment, but is especially important for complex data environments. It covers a broad range of use cases all within one tool and has become a widely adopted industry standard.
Spark provides a core data processing engine that has additional specialized libraries on top and flexible integrations into different languages, storage systems, and cluster managers which ultimately provides data engineers with a critical tool for managing, transacting, and ensuring the validity of the data in their environments.
Learn more about Acceldata’s integrations and especially how to run Spark with Acceldata Pulse.







