
























































.svg)



































.png)
🔍 The Real Problem We Face with Data Today
In every modern organization today, data is the lifeblood. We rely on it for decision-making, powering dashboards, training ML models, and more. But there's a silent problem that persists in almost every data pipeline, and it doesn't get enough attention:
✅ Bad data is more dangerous than no data.
Over the last few months, I’ve been working with the Acceldata Data Observability Cloud (ADOC) platform — a unified solution for monitoring, governing, and improving data quality. In this blog, I’ll take you through:
- The real-world problems I encountered in our data pipelines
- The exact features I tested in ADOC
- How those features helped solve the problems
- Examples and insights from actual scenarios
Let’s dive in.
⚠️ The Data Quality Problem — What We’re Really Dealing With
In complex data environments with multiple sources (ERP, CRM, logs, etc.), data issues don’t always look like bugs. They hide in plain sight:
Real Examples:
- Missing/null values in critical columns, leading to broken dashboards.
- Duplicate records inflating customer or revenue counts.
- Schema drift, where upstream teams add or remove fields without notice.
- Data drift, where the data content itself shifts silently — like a column that used to hold percentages now showing raw numbers.
The result?
- Decision-makers lose trust in data.
- Engineers lose hours debugging.
- Stakeholders get inaccurate insights.
This is where ADOC stood out for me.
🔍 What is ADOC by Acceldata?
ADOC is a Data Observability Platform that gives you end-to-end visibility into data pipelines, health, and quality. Instead of reacting to issues after they break things, ADOC helps detect, prevent, and alert on them in real time.
I tested the following features in detail:
- ✅ Data Quality (DQ) Checks
- 🔄 Schema Drift Detection
- 📉 Data Drift Monitoring
Let me explain each — with examples.
✅ 1. Data Quality (DQ) Checks — First Line of Defense
Data Quality Checks in ADOC are configurable rules that continuously monitor your datasets and alert you when something breaks your defined quality thresholds.
a. Null Value Check
Problem
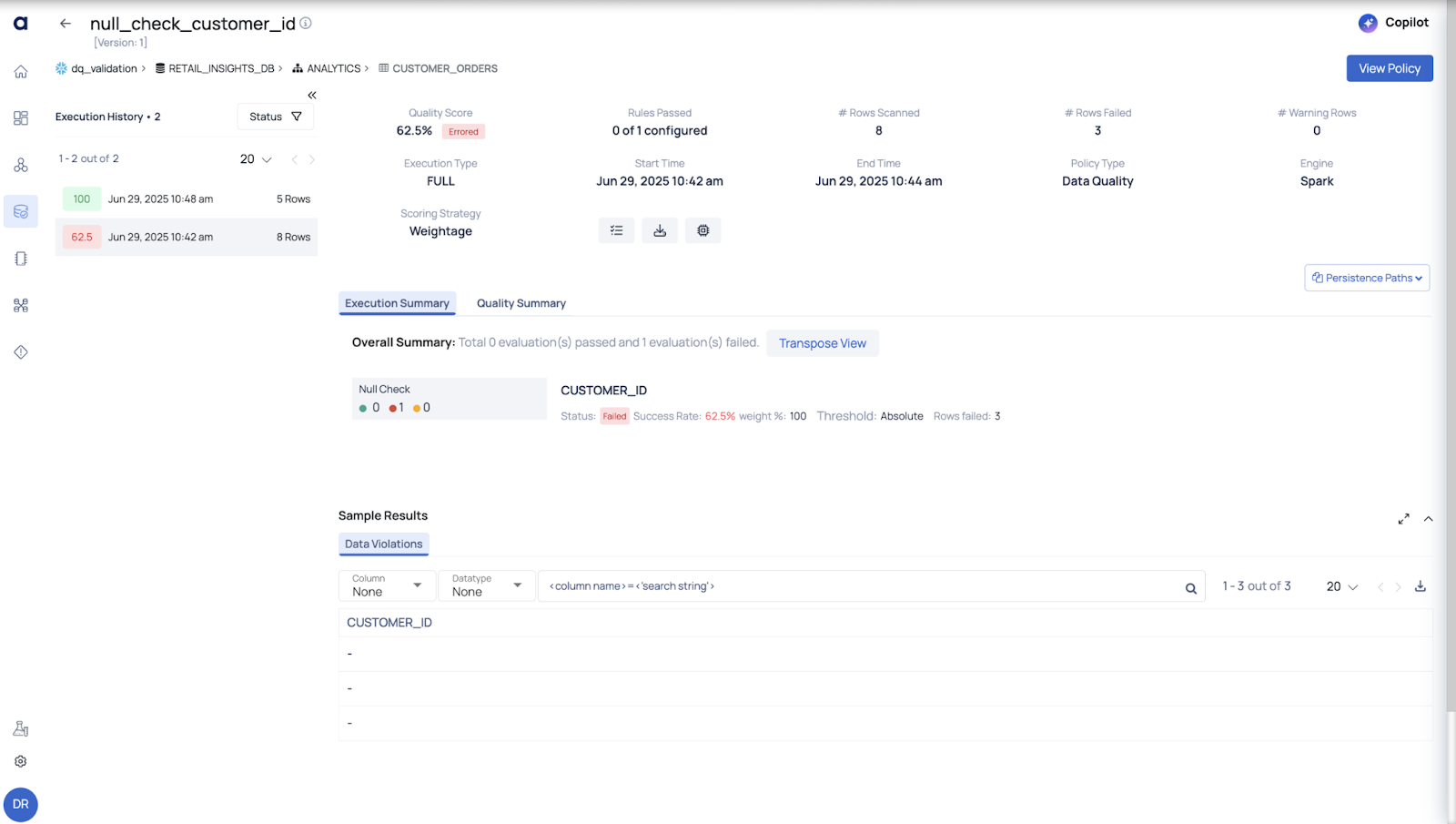
In a customer_orders table, I noticed many entries had NULL in the customer_id column — which is supposed to be a primary field.
How ADOC Helped
I created a DQ policy that checks for null values in key columns. As soon as the rate of nulls in customer_id exceeded 1%, ADOC flagged it and alerted the team.
To implement this, we created a Data Quality (DQ) policy specifically designed to check for null values in key columns such as customer_id. As part of the validation process, we inserted sample data containing null values in the customer_id field to test the effectiveness of the policy.
Once the DQ policy was in place, the system automatically scanned the data. When the null rate for customer_id exceeded the defined threshold of 1%, the policy was triggered. ADOC detected the issue and flagged it immediately. As a result, an alert notification was generated and sent to the relevant team to take corrective action.
This helped ensure that any data integrity issues were identified early and could be addressed proactively.
✅ Outcome: We caught a broken ingestion job early, before those rows entered production reports.
b. Duplicate Row Detection
Problem
A deduplication logic failed silently, resulting in double counting of orders in our monthly reports.
How ADOC Helped
I enabled a DQ policy to check for duplicate rows based on order_id. ADOC found multiple records with the same order_id, and I got a detailed report of where and when it started happening.
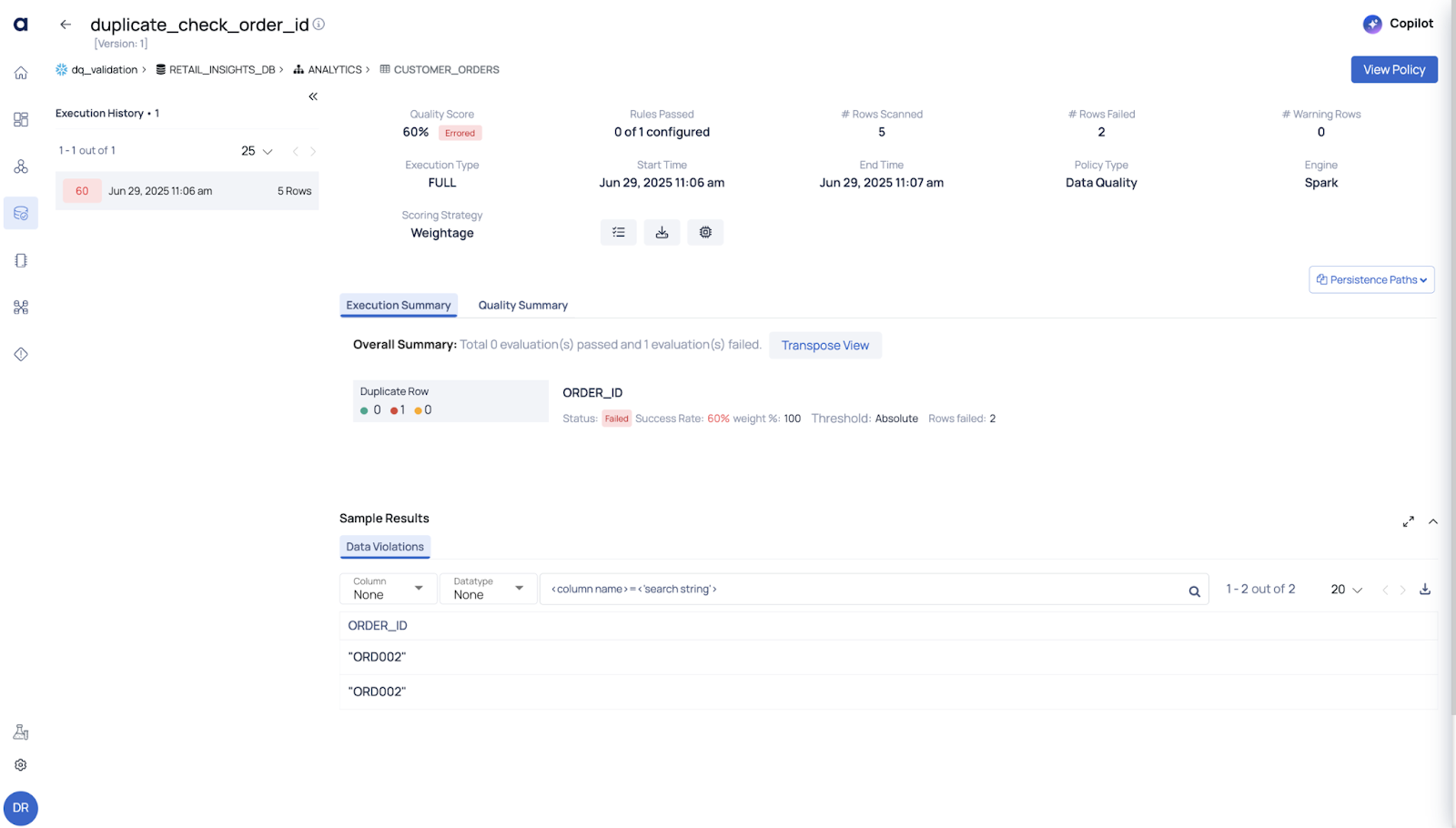
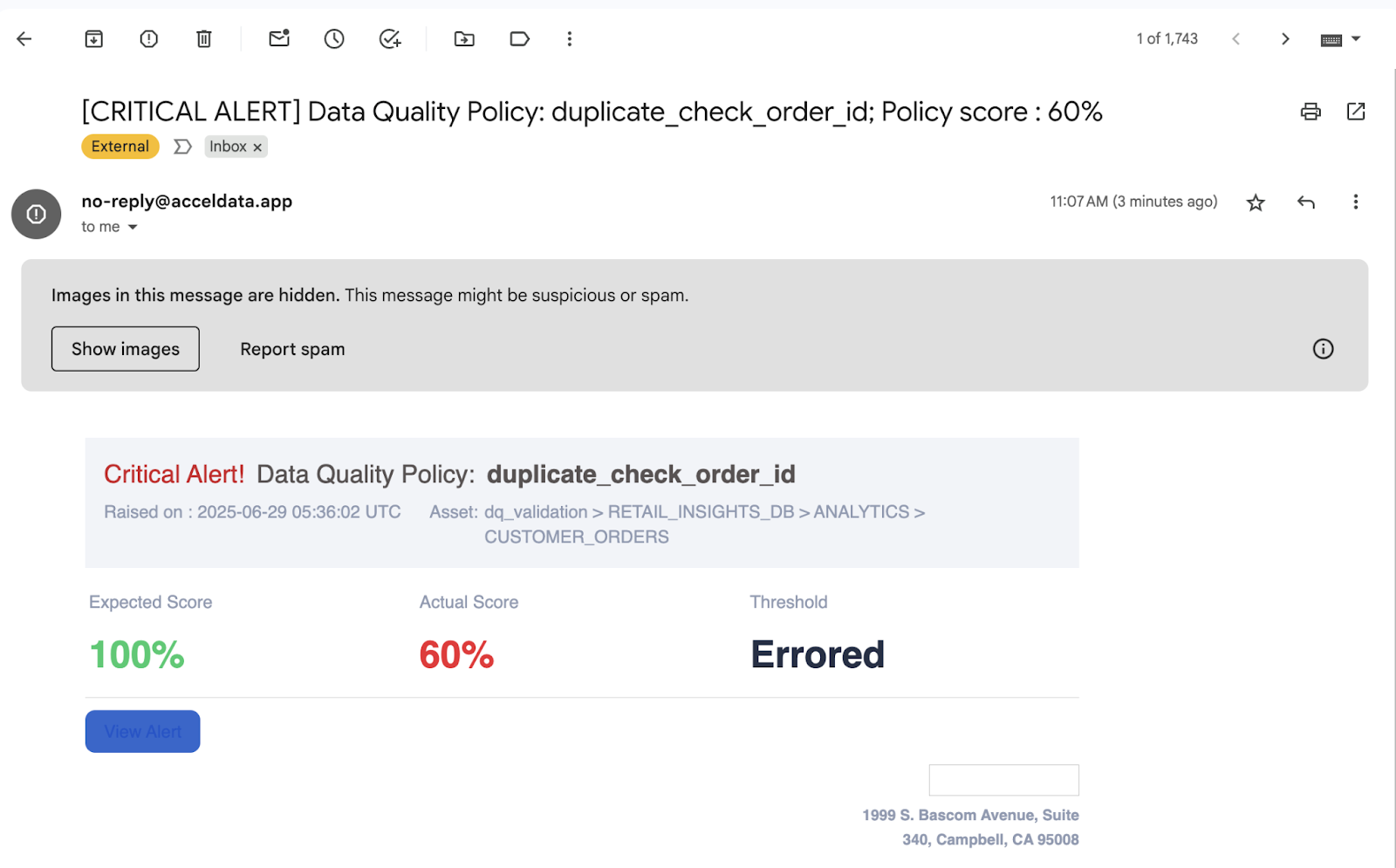
✅ Outcome: We fixed the job, restored trust in the metrics, and documented the issue for prevention.
c. User-Defined Rules
Problem
Business logic required that all order_date values be in the past. However, due to timezone mismatches in ETL, some rows had future dates.
How ADOC Helped
I created a custom rule in ADOC:
order_date < current_dateIt ran daily, caught violations, and alerted us whenever future dates were detected.
✅ Outcome: Clean, validated data ensured confidence in delivery and forecast models.
🔄 2. Schema Drift Detection — Silent Breakers of Pipelines
Schema drift happens when the structure of your data (columns, data types, etc.) changes without warning.
Example:
We have a pipeline sourcing data from a marketing platform. The upstream team changed a column name from utm_campaign to utm_campaign_name.
Impact
Our dashboards went blank — the visualization tool was still expecting the old column name.
How ADOC Helped
ADOC automatically tracked the schema version of the table. It flagged the schema drift and generated a diff report showing exactly what changed and when.
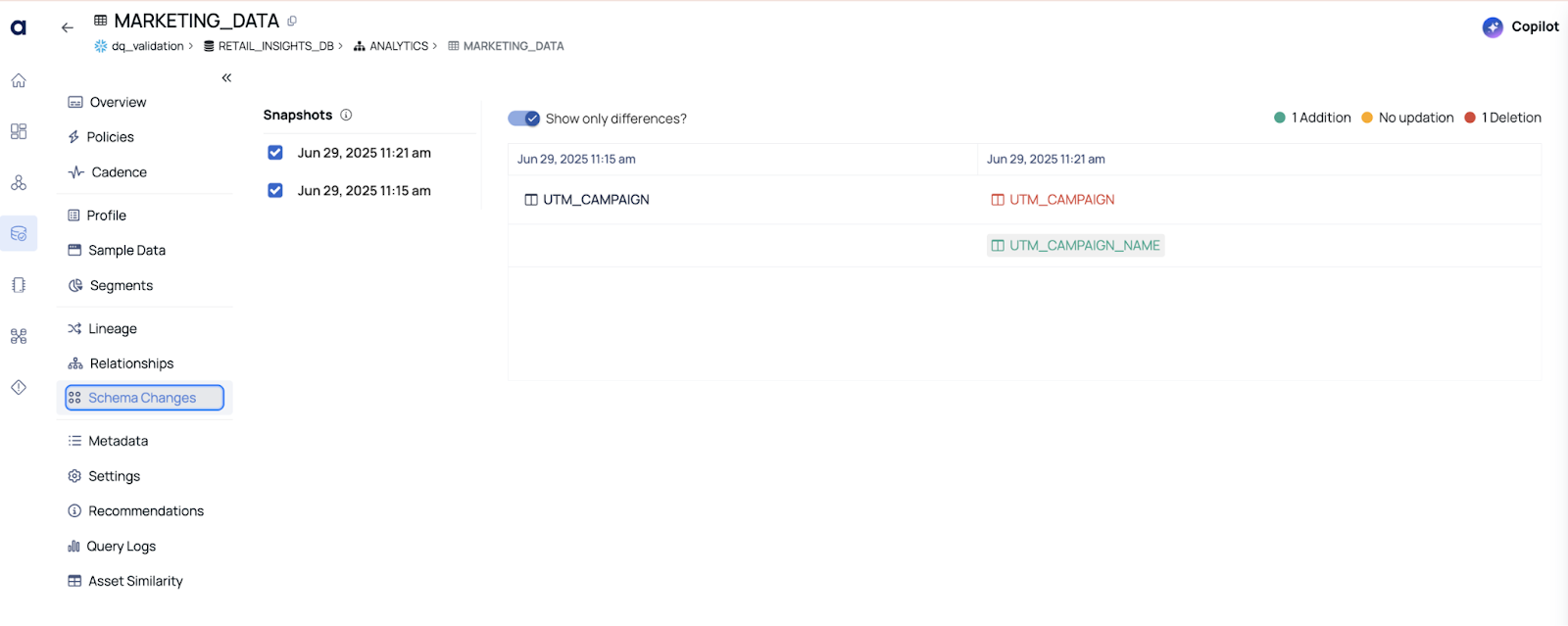
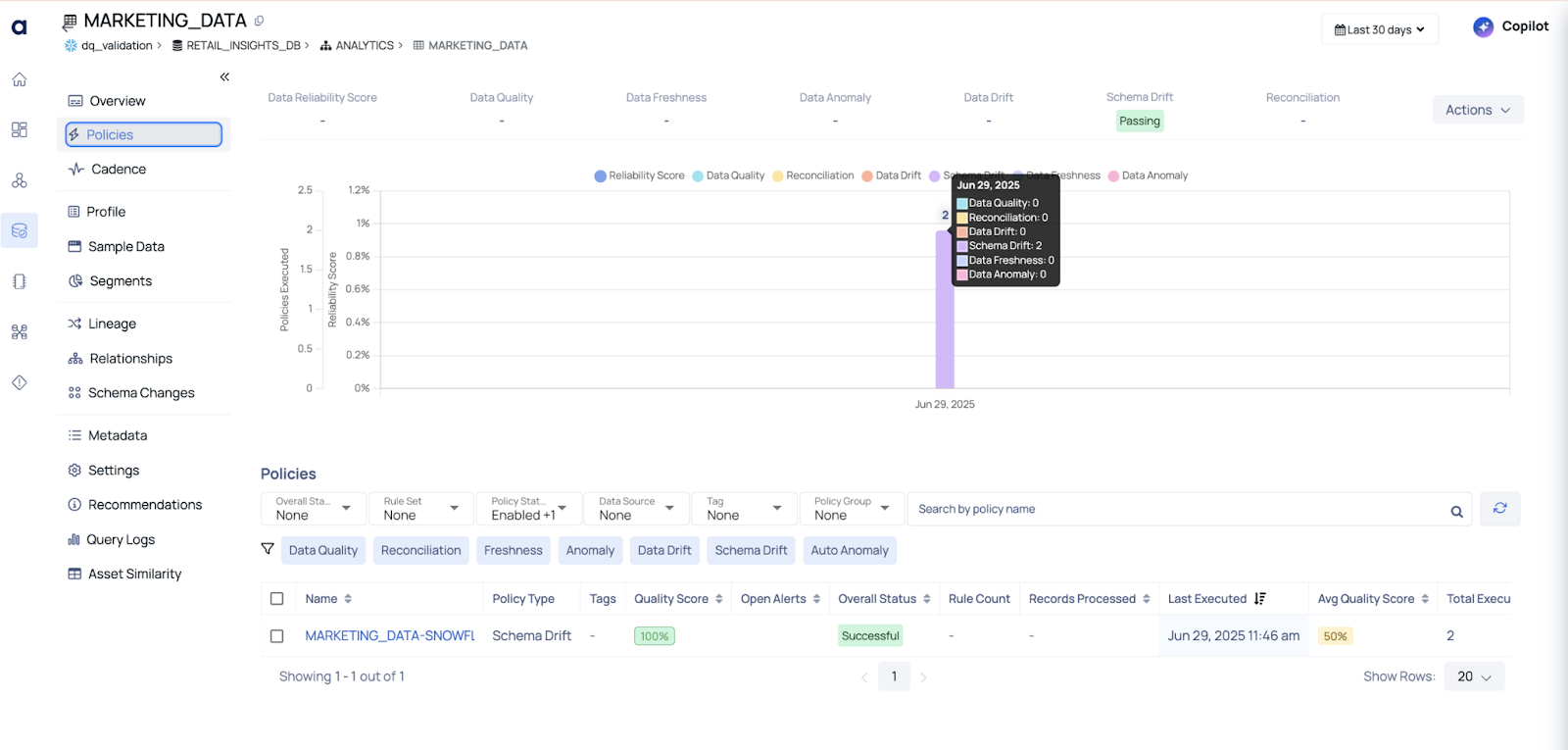
✅ Outcome: We were able to fix the dependency quickly — and more importantly, we started monitoring schema versions across all critical tables.
📉 3. Data Drift Monitoring — Catch the Unexpected
Even if the schema stays the same, the values inside the columns can change in pattern or distribution. This is called data drift, and it’s incredibly hard to catch manually.
Real Example
In our transactions table, the transaction_amount column usually follows a bell curve between $100 and $3000.
Suddenly, we noticed an increase in $0 transactions — not technically wrong, but definitely suspicious.
How ADOC Helped
ADOC monitors statistical properties of data:
- Mean
- Distinct Values
- Min/max values
- Standard deviation
I set thresholds for acceptable distribution patterns. When the transaction_amount pattern shifted, ADOC raised a data drift alert.
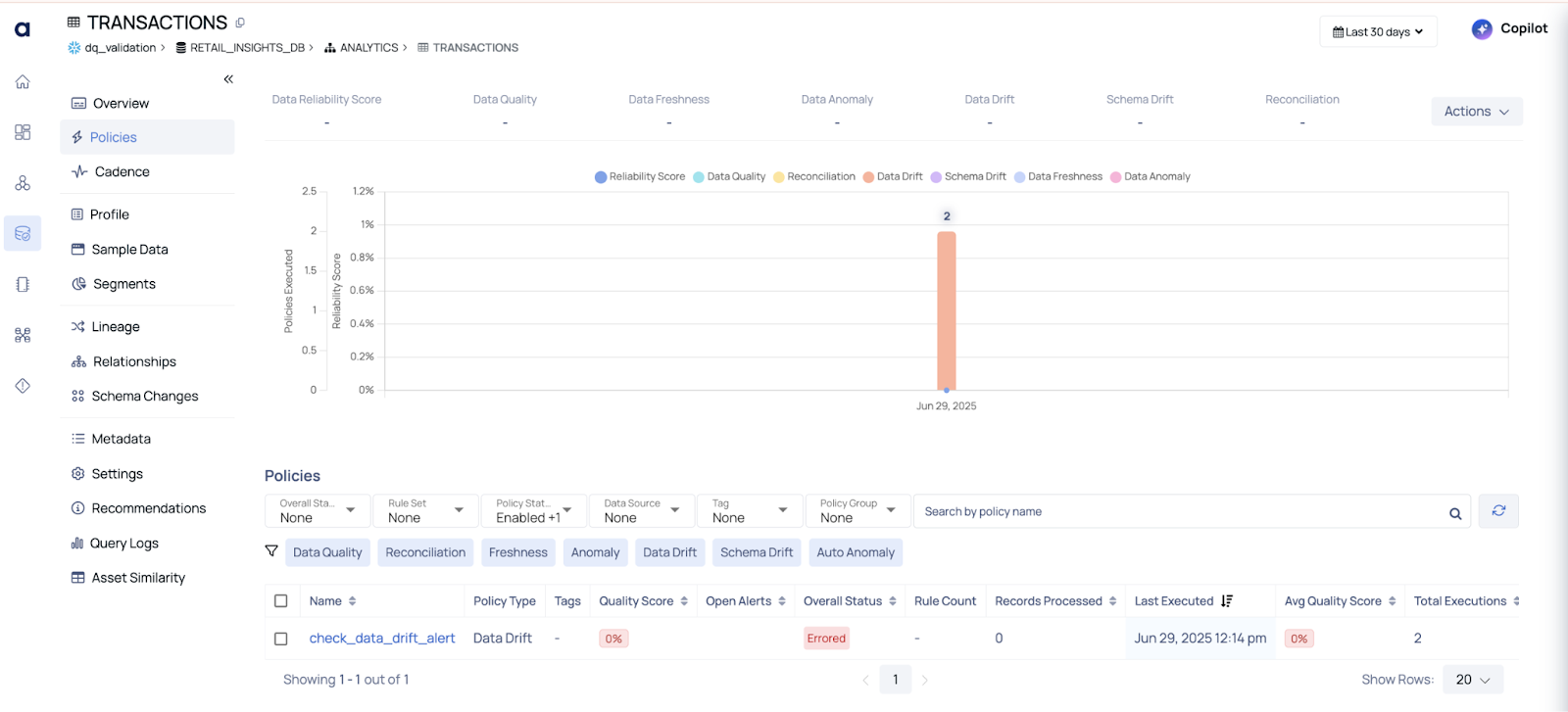
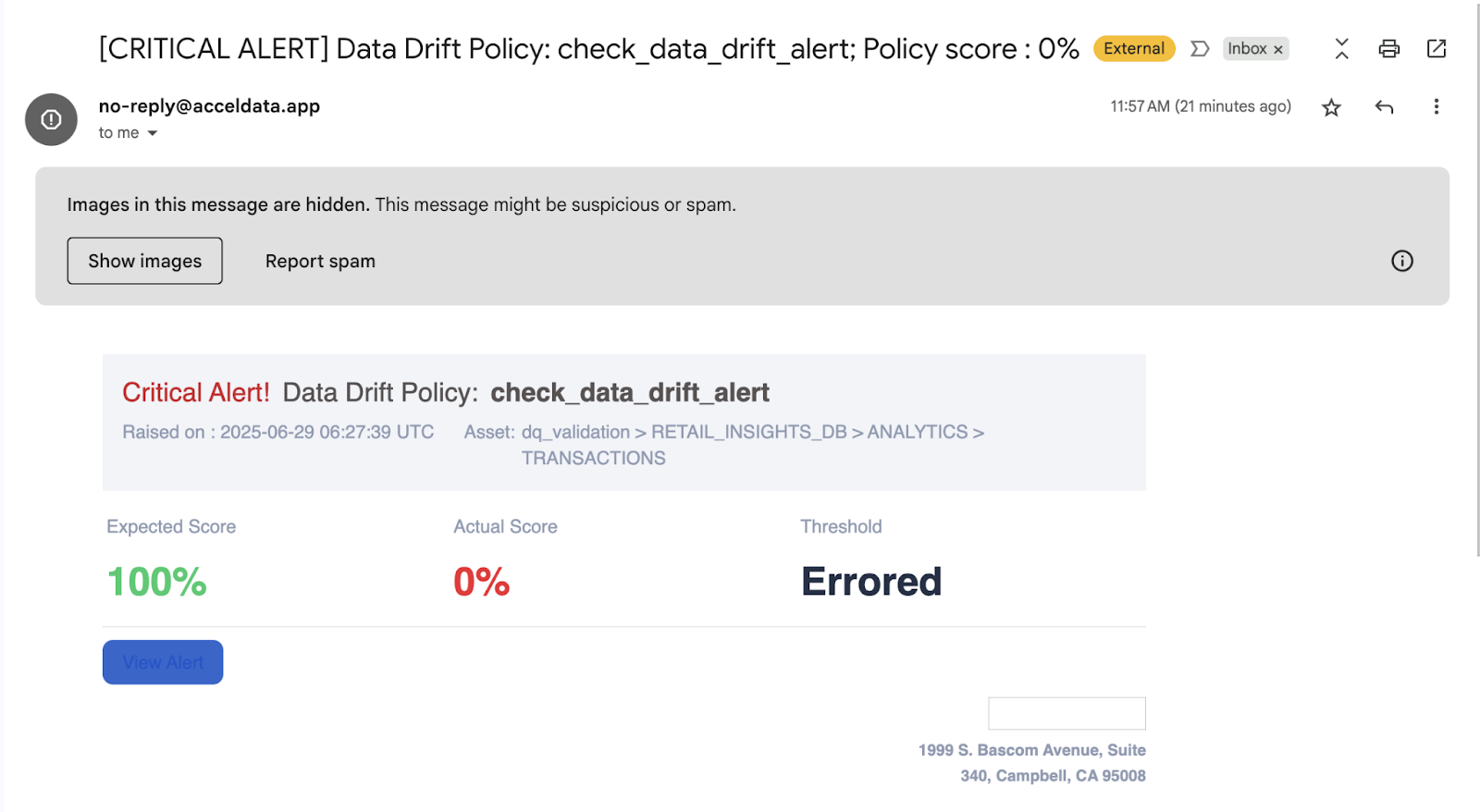
✅ Outcome: We found an upstream bug in a new payment provider integration — and fixed it before it corrupted our analytics.
🧠 Why This Matters — Beyond Just “Fixing Bugs”
Most data teams spend 60–80% of their time debugging pipeline issues. With ADOC:
- We moved from reactive to proactive monitoring
- We built confidence and trust in our data across teams
- We reduced MTTR (Mean Time to Resolution) when issues occurred
And because ADOC tracks data health over time, we could visualize trends — which helped us justify investments in pipeline quality to leadership.
🛠️ Final Thoughts: Observability is Not a Luxury, It’s a Necessity
Data Observability is not just a nice-to-have anymore. As data ecosystems grow, the chance of failure multiplies. What you need is a smart platform that watches your data even when you can’t.
ADOC gave us:
- Comprehensive Data Quality checks
- Reliable Schema & Data Drift Detection
- Actionable alerts and rich metadata context
If your team is tired of constantly fixing broken reports, wondering why numbers don’t match, or trying to trace data issues in the dark — it’s time to look at platforms like Acceldata ADOC.
📬 Let’s Talk
Tired of chasing bad data? Let ADOC show you a better way.
👉 Schedule your demo and see how real observability can stop issues before they spread.







