








































.svg)





New
Announcing our European expansion to help enterprises scale AI with data sovereignty. Read the news →
Platform Overview

Data & AI Observability
Agentic Data Engineering
Data Warehousing
Agentic Runtime
Agentic Data Management
Hadoop Modernization
Platform Overview
Everything you need to build, govern, and scale data and AI workloads—one unified platform.
xLake Architecture
Manage your data estate under one platform
Explore Integrations


Data & AI Observability
Monitor, detect, and resolve data and AI issues with end-to-end observability across pipelines.
Explore
Agentic Data Engineering
Build, orchestrate, and run data pipelines with intelligent agents that automate the entire engineering workflow.
Explore ADE
Data Warehousing
Query your lakehouse in-place with Velox-accelerated performance. 10x faster than traditional warehouses.
Explore Data Warehousing
CAPABILITIES






Agentic Runtime
Distributed training, high-throughput inference, and GPU notebooks—everything you need for production AI.
Explore
CAPABILITIES






Agentic Data Management
Build, deploy, and manage intelligent agents to automate and optimize data operations.
Explore ADM

Industries
Browse solutions to help you solve the complex business challenges unique to your industry.
Explore Case Studies
Resources
Browse materials to help you access the tools, guides, and insights essential to your workflows.








Company
Learn about our mission, leadership, and vision driving modern data operations forward.












Products

Industry
Resources
Company

Back
Platform Overview
Data & AI Observability
Agentic Data Management
Agentic Data Engineering
Data Warehousing
Data Science
Data Platform Modernization
Back
Industries
Browse solutions to help you solve the complex business challenges unique to your industry.
Explore Case Studies
Back
Resources
Browse materials to help you access the tools, guides, and insights essential to your workflows.
Back
Company
Learn about our mission, leadership, and vision driving modern data operations forward.
Back
Platform Overview
Everything you need to build, govern, and scale data and AI workloads—one unified platform.
xLake Architecture
Manage your data estate under one platform
Explore Integrations
Back
Data & AI Observability
Monitor, detect, and resolve data and AI issues with end-to-end observability across pipelines.
Explore
Back
Agentic Data Management
Build, deploy, and manage intelligent agents to automate and optimize data operations.
Explore ADM
Back
Agentic Data Engineering
Build, orchestrate, and run data pipelines with intelligent agents that automate the entire engineering workflow.
Explore ADE
Back
Data Warehousing
Query your lakehouse in-place with Velox-accelerated performance. 10x faster than traditional warehouses.
Explore Data Warehousing
CAPABILITIES
Back
Agentic Runtime
Distributed training, high-throughput inference, and GPU notebooks—everything you need for production AI.
Explore
CAPABILITIES
Products
Platform Overview
Data & AI Observability
Agentic Data Management
Agentic Data Engineering
Data Warehousing
ML & AI Applications
Business Applications
Data Platform Modernization
Platform Overview
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin mi
Explore Platform
Data & AI Observability
Monitor, detect, and resolve data issues with end-to-end observability across pipelines.
Explore ADOC
Agentic Data Management
Monitor, detect, and resolve data issues with end-to-end observability across pipelines.
Explore ADM
Agentic Data Engineering
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin mi nibh
Explore ADE
Data Warehousing
AI-powered observability and optimization for Hadoop and big data environments.
Explore Data Warehousing



ML & AI Applications
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin
Explore ML & AI Applications




Data & AI Observability
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse so
Explore Business Applications
Open Data Platform
An open-source data platform for Hadoop modernization, flexibility, and long-term control.
Explore ODP
AI-Assisted Pipelines. From Plain Language to Spark Deployment.
Describe your pipeline intent. xLake generates, validates, and deploys a production-ready Spark job — no DAG coding, no orchestration expertise, no manual configuration.
Request a live demo

.png)
TRUSTED BY ENTERPRISE DATA TEAMS WORLDWIDE











Intent in. Production pipeline out
Simply describe what the pipeline needs to do — in natural language. No schema syntax. No query logic. No prompt engineering.
xLake's AI interprets your intent, generates production-grade Spark (Java or Python), validates it against your live environment, and registers it with full metadata, lineage, and audit trail.
No specialist hand-off.
No intermediary steps.
No visual builder with guardrails.
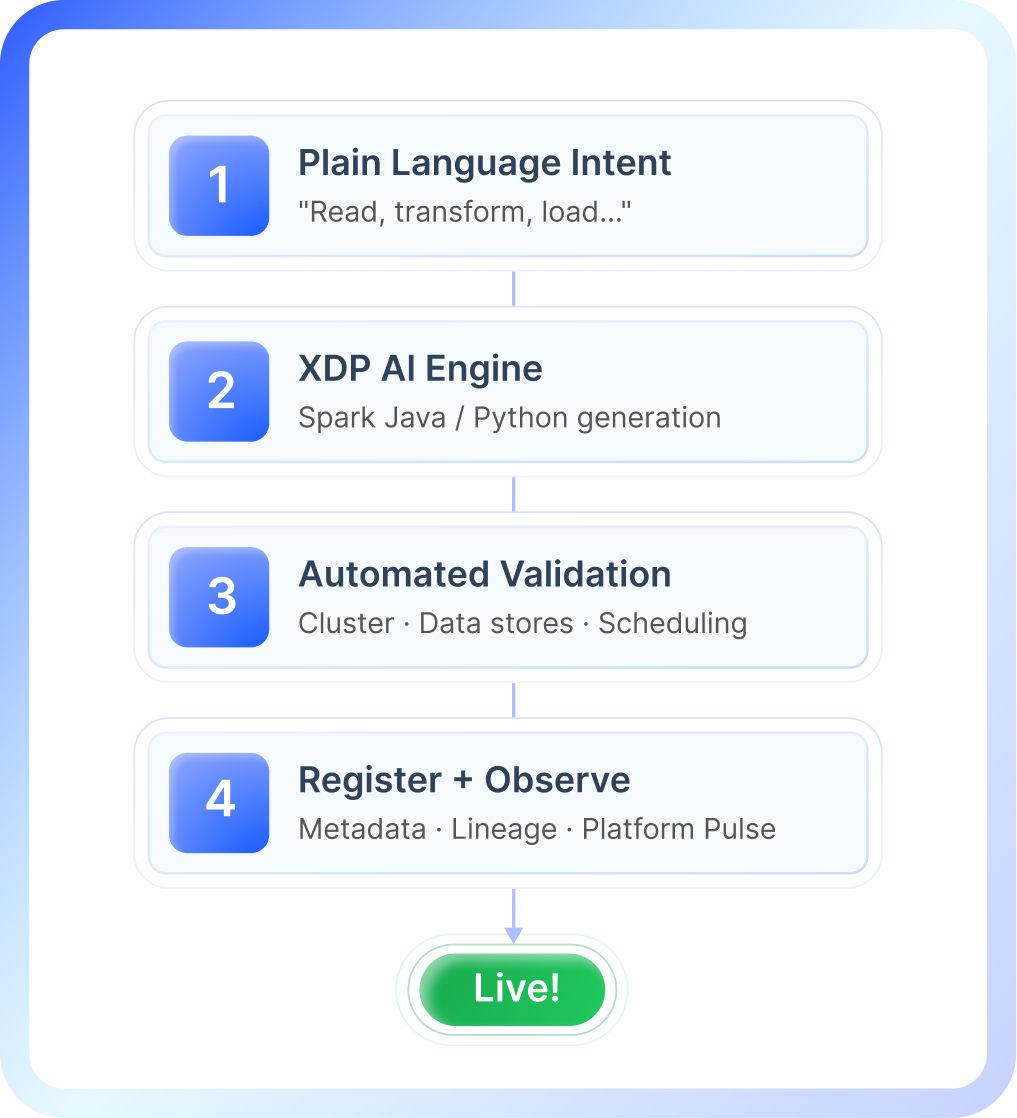
How It Works
Plain-language input to monitored, production-ready pipeline — without leaving xLake.
1


Describe your intent in plain language.

Source, transformation, destination. No schema knowledge. No orchestration expertise required.
2
xLake generates production-grade Spark code.
Java or Python — complete and executable. Not a scaffold. Not a stub.
3
Automated validation runs before anything touches production.
Live cluster config, data store connectivity (ODP, S3, HDFS, Vast), scheduling dependencies — resolved at generation time, not at runtime.
4
The pipeline is registered with full context.
Metadata, dependency map, audit trail — committed automatically. No manual tagging. No separate governance step.
5
Lineage and monitoring connect immediately.
Visible in Platform Pulse from the moment it's registered. Observability starts on day one. Plain-language input to monitored, production-ready pipeline — without leaving xLake.
The Full Loop. One Motion.
Most platforms stop at pipeline generation. You still validate manually, wire lineage separately, and configure orchestration. xLake changes that.
Step
What xLake Does
Status

Author
Generates Spark Java or Python from plain-language intent — complete, executable, production-grade code
Validate
Auto-validates against live cluster config, data stores (ODP, S3, HDFS, Vast), and scheduling constraints
Register
Commits the job with metadata, dependency map, and full audit trail — no manual tagging required
Observe
Connects natively to Platform Pulse for lineage and runtime monitoring — active from day one
Production-Readiness Is the Output
xLake validates every AI-generated pipeline before a single line executes in production:
Live cluster config
Checked against your actual Spark environment, not a generic template
Checked against your actual Spark environment, not a generic template
Data store connectivity
ODP, S3, HDFS, and Vast confirmed before registration
ODP, S3, HDFS, and Vast confirmed before registration
Scheduling constraints
Dependencies resolved at generation time, not discovered at runtime
Dependencies resolved at generation time, not discovered at runtime

Governance and Lineage Are Native
Every xLake-generated pipeline is automatically registered with:

Full Metadata
Complete metadata committed at generation time. Every field, every dependency — tracked and searchable from day one.

Data Lineage
Lineage tied directly to the generation step — not added post-hoc. Trace data from source to destination instantly.

Audit Trail
Complete audit trail for compliance and debugging. Every generation event logged — who, what, when, and why.

Built for Real Enterprise Workloads
xLake is designed for mid-to-large enterprises running Spark at scale — where pipeline cycles
slow down the entire data org and fragmented toolchains create risk without visibility
Running workloads across ODP, S3, HDFS, or Vast? xLake is built for this environment.

Full Metadata
ODP, S3, HDFS, and Vast — all supported natively. xLake is built for the environments enterprises actually run.
Spark at Scale
xLake handles the complexity that comes with large-scale Spark deployments — where a single misconfigured pipeline can cascade across the entire data org.
Reduced Pipeline Cycle Time
From intent to production in minutes, not weeks. Eliminate the back-and-forth between data engineers, architects, and governance teams.
Unified Risk Visibility
Replace fragmented toolchains with a single platform that provides complete risk visibility from pipeline creation to production monitoring.
How xLake Compares
Visual platforms still require you to construct pipelines step by step. Traditional tools still require DAG expertise. xLake removes both prerequisites.

Language-first, intent-driven authoring
Automated pre-production validation
Orchestration knowledge required
Native lineage connected to generation
Single closed-loop platform
xLake
Visual/No-Code Platforms
Traditional Tools







Dominate with Data
40%
reduction in pipeline
downtime
downtime

30%
faster time-to-model
deployment
deployment
25%
lower cluster costs
99.9%
SLA adherence on
migrated workloads
migrated workloads
Got Questions? Get Clarity
Q1. Do I need to know Spark, Java, or Python to use xLake?
No. xLake is designed so that engineers and data practitioners can describe pipeline intent in plain language — what data to move, how to transform it, and where it should land. xLake handles all code generation. Knowledge of Spark syntax or orchestration frameworks is not required to author a production-ready pipeline.
Q2. What data stores and environments does xLake support?
xLake validates and connects to ODP, S3, HDFS, and Vast. Connectivity to your data stores is confirmed automatically at generation time — before the pipeline is ever registered or executed in production.
Q3. How does xLake ensure the generated pipeline is actually production-ready?
Every generated pipeline goes through automated pre-production validation: live cluster configuration is checked against your actual Spark environment, data store connectivity is confirmed, and scheduling dependencies are resolved at generation time. Nothing reaches production without passing these checks.
Q4: What happens to lineage and governance after a pipeline is generated?
Lineage, metadata, and a full audit trail are committed automatically as part of the generation step — not added manually afterward. There is no separate governance tool to configure and no manual tagging required. Everything is registered in xLake and visible in Platform Pulse from the moment the pipeline is created.
Q5: Can xLake generate both Java and Python Spark jobs?
Yes. xLake generates complete, executable Spark code in either Java or Python — not scaffolds or stubs. The output is a fully formed pipeline ready for production use.
Q6: How is xLake different from visual or no-code pipeline builders?
Visual platforms require you to construct pipelines step by step using a builder interface, and they typically stop short of automated validation, native lineage, and closed-loop registration. xLake starts from plain-language intent and handles the full loop — authoring, validation, registration, and observability — inside a single platform without manual handoffs between tools.
Ready to get started
Explore all the ways to experience Acceldata for yourself.
