








































.svg)





New
Announcing our European expansion to help enterprises scale AI with data sovereignty. Read the news →
Platform Overview

Data & AI Observability
Agentic Data Engineering
Data Warehousing
Agentic Runtime
Agentic Data Management
Hadoop Modernization
Platform Overview
Everything you need to build, govern, and scale data and AI workloads—one unified platform.
xLake Architecture
Manage your data estate under one platform
Explore Integrations


Data & AI Observability
Monitor, detect, and resolve data and AI issues with end-to-end observability across pipelines.
Explore
Agentic Data Engineering
Build, orchestrate, and run data pipelines with intelligent agents that automate the entire engineering workflow.
Explore ADE
Data Warehousing
Query your lakehouse in-place with Velox-accelerated performance. 10x faster than traditional warehouses.
Explore Data Warehousing
CAPABILITIES






Agentic Runtime
Distributed training, high-throughput inference, and GPU notebooks—everything you need for production AI.
Explore
CAPABILITIES






Agentic Data Management
Build, deploy, and manage intelligent agents to automate and optimize data operations.
Explore ADM

Industries
Browse solutions to help you solve the complex business challenges unique to your industry.
Explore Case Studies
Resources
Browse materials to help you access the tools, guides, and insights essential to your workflows.








Company
Learn about our mission, leadership, and vision driving modern data operations forward.












Products

Industry
Resources
Company

Back
Platform Overview
Data & AI Observability
Agentic Data Management
Agentic Data Engineering
Data Warehousing
Data Science
Data Platform Modernization
Back
Industries
Browse solutions to help you solve the complex business challenges unique to your industry.
Explore Case Studies
Back
Resources
Browse materials to help you access the tools, guides, and insights essential to your workflows.
Back
Company
Learn about our mission, leadership, and vision driving modern data operations forward.
Back
Platform Overview
Everything you need to build, govern, and scale data and AI workloads—one unified platform.
xLake Architecture
Manage your data estate under one platform
Explore Integrations
Back
Data & AI Observability
Monitor, detect, and resolve data and AI issues with end-to-end observability across pipelines.
Explore
Back
Agentic Data Management
Build, deploy, and manage intelligent agents to automate and optimize data operations.
Explore ADM
Back
Agentic Data Engineering
Build, orchestrate, and run data pipelines with intelligent agents that automate the entire engineering workflow.
Explore ADE
Back
Data Warehousing
Query your lakehouse in-place with Velox-accelerated performance. 10x faster than traditional warehouses.
Explore Data Warehousing
CAPABILITIES
Back
Agentic Runtime
Distributed training, high-throughput inference, and GPU notebooks—everything you need for production AI.
Explore
CAPABILITIES
Products
Platform Overview
Data & AI Observability
Agentic Data Management
Agentic Data Engineering
Data Warehousing
ML & AI Applications
Business Applications
Data Platform Modernization
Platform Overview
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin mi
Explore Platform
Data & AI Observability
Monitor, detect, and resolve data issues with end-to-end observability across pipelines.
Explore ADOC
Agentic Data Management
Monitor, detect, and resolve data issues with end-to-end observability across pipelines.
Explore ADM
Agentic Data Engineering
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin mi nibh
Explore ADE
Data Warehousing
AI-powered observability and optimization for Hadoop and big data environments.
Explore Data Warehousing



ML & AI Applications
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin
Explore ML & AI Applications




Data & AI Observability
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse so
Explore Business Applications
Open Data Platform
An open-source data platform for Hadoop modernization, flexibility, and long-term control.
Explore ODP
Pipeline Orchestration · Kubernetes-Native
Pipeline Orchestration
on Kubernetes - With Full Visibility
Runtime Visibility, Compute Control, fewer SLA Failures for enterprise-grade pipelines on your infrastructure — it's more than just success metrics.

TRUSTED BY ENTERPRISE DATA TEAMS WORLDWIDE











The Problem
The Problem With How Most Teams Run Pipelines Today
Most pipelines fail silently. xLake closes that gap.

False Positives, Invisible Problems
DAGs succeed while Spark jobs silently consume 3× expected resources and downstream tasks queue behind them

No Runtime Visibility
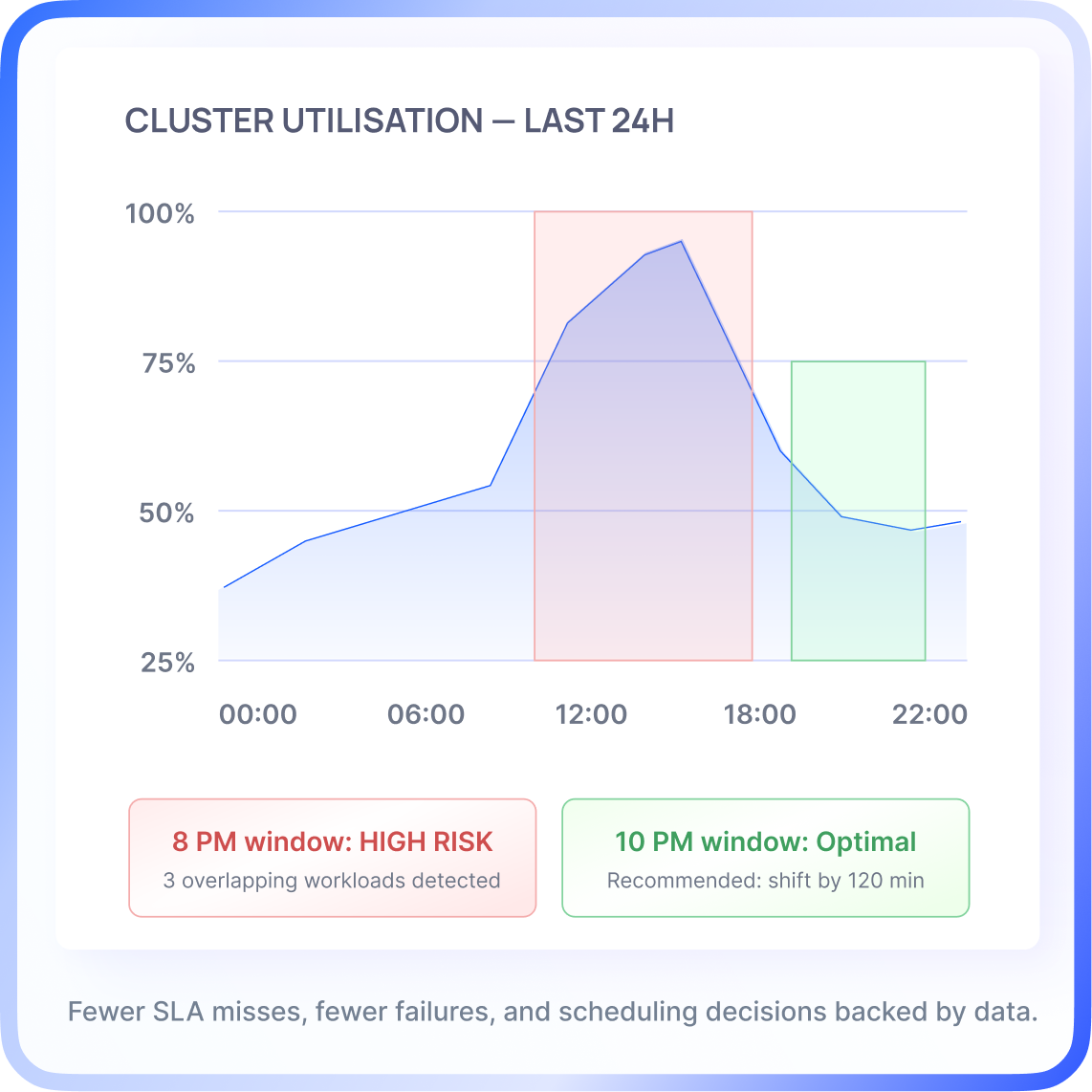
You can't see which queries are creating contention in the 8 PM scheduling window, only that something went wrong afterward

Managed compute lock-in
Platforms that handle orchestration for you do it on their infrastructure, at their pricing, under their constraints

Scaling ceilings
Legacy platforms hit concurrency limits you're now engineering around manually

Fragmented toolchains
Spark, Trino, and Python workloads each need separate tooling, separate logging, separate everything
Compute Control
Run Pipelines on Your Kubernetes. Keep Control of Your Compute.
xLake deploys directly onto your Kubernetes clusters — EKS, AKS, GKE, or on-premises. Your data stays in your environment. Your compute plane stays under your control.
.png)
Runtime Observability
See Inside Every Running Pipeline — Not Just Whether It Passed
More than just DAG Success Status. xLake answers questions that actually matter:


Why did that Spark job consume 40% more memory than last Tuesday?
Which Trino queries are creating contention in the 8 PM scheduling window?
What's the per-job resource footprint across every namespace?

Ship Pipelines Faster With AI-Assisted DAG Authoring
Describe a pipeline in plain language. Upload an existing YAML or SQL spec. xLake generates the DAG. Your engineer reviews, adjusts, and ships.

1
xLake deployed inside your AWS VPC
2
Kubernetes Dashboard and DataPlane Helper ready
3
Control plane traffic secured — data operations never leave your VPC
4
Zero vendor access to your data. Zero egress surprises.
70%
Faster time-to-pipeline.

↓ 3×
Fewer authoring errors
4x
Engineering efficiency
Prevent SLA Failures Before They Happen
Smart job window recommendations:
Analyses historical cluster utilisation and surfaces optimal scheduling windows before you commit a run.

Conflict avoidance logic:
Identifies overlapping workloads across Spark, Trino, and Python jobs and calculates contention risk in advance.
One Control Plane. Every Workload Type.
Every cost driver that legacy platforms obscure or ignore — surfaced and resolved.

Native Kubernetes deployment on customer infrastructure
Per-job runtime observability at K8s namespace level
AI-assisted DAG generation from natural language / YAML / SQL
Conflict avoidance and smart scheduling windows
Unified orchestration across Spark, Trino, JupyterHub, Python
Data sovereignty — compute stays in your environment
xLake
Standard Orchestrators
Managed Compute Platforms

Partial

Limited
Manual Writing
Spark-primary




Built for teams Running at Enterprise Scale
Where pipeline failure is a business problem. Where a missed SLA has a cost. Where teams are accountable for both reliability and efficiency.
For teams managing dozens of concurrent pipelines across hybrid environments and hitting the limits of what your current orchestrator can observe and legacy platforms can scale — xLake is built for this.
100s
Concurrent pipelines managed
≥99.9%
SLA reliability target
4+
Workload types, one control plane
0
Data leaving your environment
Ready to get started
Explore all the ways to experience Acceldata for yourself.
